오늘은 DSTC 10에서 좋은 성적을 보였던 방식에 대하여 summary한 논문을 살펴보도록 하겠습니다.
😎 DSTC TRACK2 OVERVIEW
- Intro
주최측인 알렉사 ai에서 낸 논문 부터 시작하도록 하겠습니다. 문제를 낸 이유와 데이터셋에 대한 설명 제출된 팀들의 방식이 세부적으로 설명되어 있습니다.
첫째로 출제 이유입니다. 여기서는 보다 세부적으로 Written 데이터와 Spoken 데이터의 차이에 대해 나타내고 있습니다. 차이는 다음과 같습니다. 이러한 차이를 가지는데 많은 에이전트들은 음성데이터의 음성인식결과로 운영된다는 점, 그리고 Spoken 데이터는 어노테이션 데이터가 많이 없다는 점을 지적했습니다.

본 대회에서 Track2 의 핵심은 Spoken이었다는 것이고, 이러한 데이터에서 Sub track1과 2로 나뉘어 dst를 진행하는 것과 적절한 faq를 찾는 문제로 나뉘었습니다. 팀들은 각각 서브트랙에 참여 할 수 있었고 5가지의 제출결과를 낼 수 있었고 21개의 팀에서 총 99개의 제출 결과가 나왔다고 합니다.
- DATA
데이터를 만든 형식은 사람과 사람 대화 형식으로 센프란시스코 관광정보를 담고 있습니다. 세션마다 유저 역할과 에이전트 역할을 정해 줬으며, 유저 역할 사람에겐 특정한 Goal을 줬고, 에이전트는 그 목적에 맞는 내용을 DB에서 찾아 응답을 만들었다고 합니다. VAL TEST 데이터 통합하여 890 세션을 녹음했고 총 45 시간이라고 합니다.
각각의 데이터셋 차이는 DSTC10 데이터셋이 멀티오즈 2.0이나 DSTC9과 다른 점은 텍스트 형태로 되어있고, 멀티오즈는 7가지의 케임브릿지 지역의 도메인을 기반으로 되어있다. 이러한 형식을 따라 센프란시스코 지역의 데이터를 만들어 DSTC9에서 공개했고 호텔 레스토랑 어트렉션 도메인만 다루었다. 하지만 멀티오즈의 각 도메인 엔티티 보다 훨씬 더 많은 엔티티를 가지고 있다. 추가적으로 지식 SNIPPET을 다루기 위한 FAQ형식의 리스트도 구축했다. 그래서 이러한 과정을 통해 DSTC10에서는 이것을 기반으로 SPOKEN 형태로 크라우드 소싱을 통해 만들었다.
결과적으로 데이터셋은 ASR 결과 인데 ASR 모델은 WAV2VEC 모델로 960시간의 리브리 스피치로 프리트레인 한 것을 사용했다. 그리고 10퍼센트의 VAL Data로 파인튜닝을 진행했다. 그리고KenLM 기반 언어모델로 10-best decoding 을 진행했다. 최종적으로 1-Best에서의 WER은 26.25였고, 10-best 후보들에 대한 oracle WER은 24.31 이였다.
- TASKS
subtrack 1 - Multi-domain Dialogue State Tracking
가장 먼저 제가 참가했던 sub track1에 대해 정리해 보도록 하겠습니다. 가장 중심적으로 수행해야 하는 역할은 유저와의 인터렉션 결과로 belief state를 예측하는 것인데 이는 가장 최신의 유저 골로 정의 됩니다. 성능지표는 또한 이전의 dst task들과 가장 다른 점은 spoken conversation이라는 점 / 많은 모델들은 텍스트 형태의 데이터로 학습되어 있고, 본 데이터는 spoken 형태 이기 때문에 미스매치 되어 성능이 좋지 않다는 문제를 해결 해야했습니다. 두번쨰는 asr 에러를 포함하고 있다는 것입니다. 이 문제는 음성대화 시스템에서 지속적으로 이슈가 있던 부분입니다.
subtrack 2 - Knowledge-grounded Dialogue Modeling
두번쨰로는 Knowledge-grounded dialogue modeling 부분입니다. 첫번째는 주어진 발화와 dialogue history를 통해 지식접근이 필요한 턴인지를 구분하는 task입니다. 본 task에서 지식접근이 필요하다고 판단할 경우 selectio파트에서는 도메인 Knowledge DB에서 적절한 지식을 추출해 냅니다. 그 후 입력 발화와 대화 문맥 골라진 지식을 종합하여 자연스러운 답변을 생성하는 턴으로 이루어집니다. 이는 DSTC9에서 처음 공개된 Task였는데, 이번에 다른 점은 역시 spoken 데이터셋에서 하는 것이라는 점 입니다.
- Baseline Model
주어진 베이스라인 모델은 Subtrack1에선 tripy로 버트 기반의 dst 모델이고, 유저 발화, 시스템 발화, dialogue state에 대해 카피 매카니즘을 적용하는 모델입니다. subtrack2에서는 두가지 모델이 제공되었는데, 모든 각각 단계에 맞추어 파인튜닝된 GPT2와 Knover가 베이스라인으로 공개되었습니다.
Knover는 gpt2대신 plato2가 사용되었고, selection부분에서 멀티 스케일 샘플링이 사용된 점, 생성에서 빔서치가 사용된 점이 다르고 dstc9에서 동일한 과제에서 가장 뛰어난 성능을 보였던 모델입니다.
🐥 여기서 잠깐 PLATO2모델이란?
plato2 모델은 오픈도메인에서 커리큘럼 러닝이라는 방식을 제안한 모델인데 dstc9에서 목적지향형 대화시스템에도 뛰어난 성과를 보인다는 것이 밝혀진 모델입니다. 이 방식은 두가지 스테이지로 나뉘는데 연두색 박스가 첫번째 stage인 coarse-grained baseline model이 general한 답변을 원투원 맵핑 방식으로 학습됩니다.
두번째 단계는 하늘색, 주황색 박스에서의 두가지 모델로 구성된 fine-grained generation, evaluation 이 다양한 답변을 생성하기 위해 동작합니다.
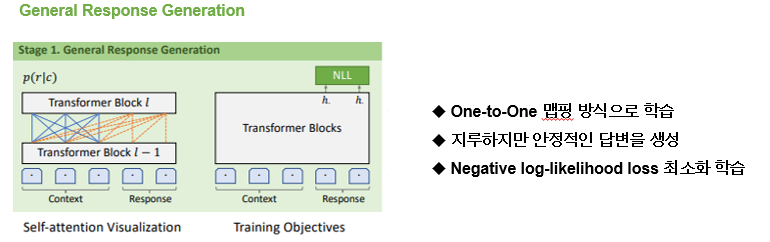
오픈 도메인 대화에서는 원투매니 형식으로 정답에 해당하는 대답이 많을 수 있는데 전통적인 방식에서는 일대일 매핑을 하기 때문에 지루하거나 일반적인 답변을 하는 경우가 많습니다. 하지만 이 방식은 안정적이고 보다 정확한 답변을 생성할 수 있습니다. 따라서 plato2는 일대일 매핑 방식으로 첫번째 coarse-grained baseline model을 학습시킵니다. 학습은 nll loss를 최소화 하는 방식으로 학습 되게 됩니다.
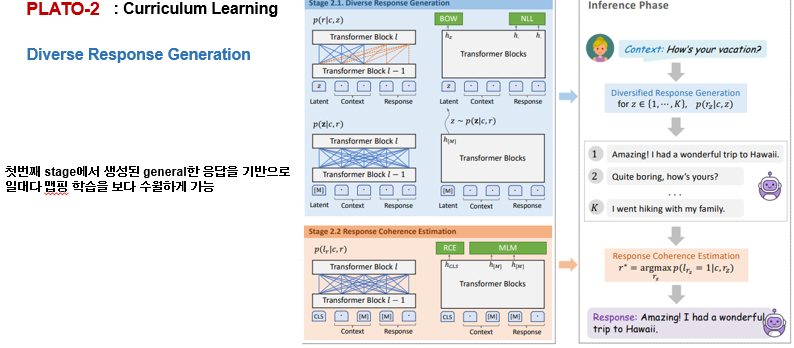
다음을 다양한 답변을 만들기 위한 방식입니다. 두번째 단계인 fine-grained 단계입니다. 여기서는 생성과 평가 단계로 나뉘게 되는데, z 라는 k-way의 카테고리컬 변수로 일치하는 응답 안에서의 latent speech act 를 이용해 생성 모델은 잠재 변수에 고유한 값을 할당함으로써 여러 개의 고품질 및 다양한 반응을 생성할 수 있습니다. 그 후 전체 문장과 일관성 유지를 위해 일관성에 대한 추정 과정을 포함합니다. 각 답변별 일관성 정도와 주어진 대화 문맥을 활용하여 계산되고 최종 답변이 생성됩니다.
그림에서 보는 것처럼 이전 연두박스에서 생성되었던 답변을 기반으로 파랑 박스에서 여러가지의 답변 스타일들이 생성되고 주황색박스에서 이전 문맥과 연관성 추정을 통해 가장 적절한 대답이 초이스 됩니다.
- Evaluation
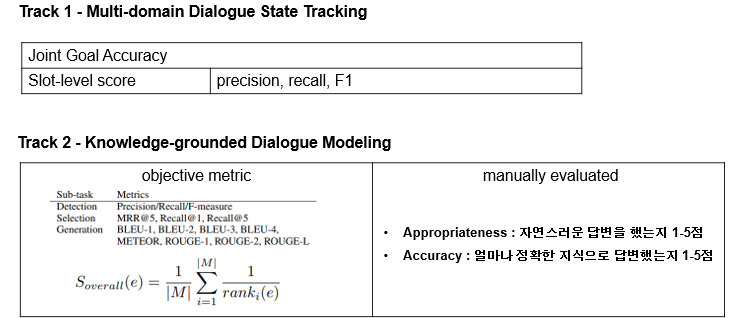
평가 방식은 다음과 같고, subtrack2는 자동평가와 휴먼 평가가 함께 진행되었습니다.
- Result
그렇다면 우수 팀들의 방식을 정리해 보도록 하겠습니다.
subtrack 1 - Multi-domain Dialogue State Tracking
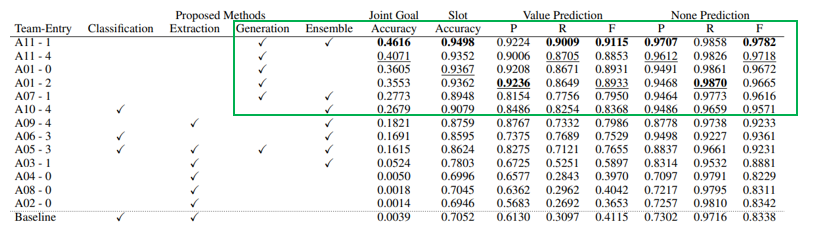
먼저 subtrack1에서의 결과를 보면 싱글 모델인지 앙상블 모델인지 dst 방식에 따라 분류를 했는데 A11팀이 최종 우승을 했고, A01팀 2등 A07팀이 3등한 팀입니다. DST 방식을 설명하자면 Classification은 value값을 채우는 것을 분류 문제로, extraction은 이전 발화들에서 추출하는 방식 그리고 생성하는 방식입니다. 베이스라인 trippy는 extraction 방식입니다.
높은 순위 팀들의 결과를 정리하자면 생성기반 모델들이 가장 좋은 성능을 보였다는 것 입니다. 생성 기반 모델들은 spoken 스타일로 바뀌며 변화된 value들에 강항성능을 보였고, 다른 방식 들은 state를 예측하는데 낮은 성능을 보였습니다.
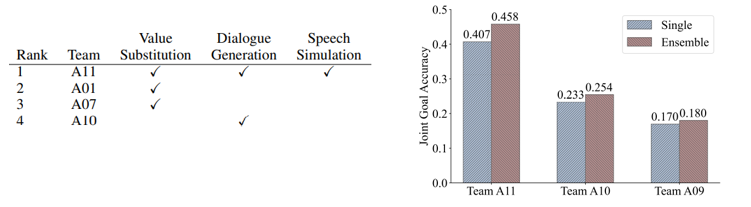
데이터 증강도 많은 영향을 미쳤다는 것을 알 수 있습니다. value substitution은 새로운 온톨로지 컨텐츠로 부터 만들어진 트레이닝 발화 방식, dialogue generation은 멀티 턴 혹은 전체 대화 단에서 새로운 대화를 생성한 방식 마지막으로 spoken형태 style을 담기 위한 speech simulation 방식이 있었습니다. 모든 방식을 활용한 A11팀이 우승한 것을 봤을 때 데이터 증강이 매우 중요하다는 것을 알 수 있음. 마지막으로 상위팀들 결과를 봤을 때 싱글모델만 사용한 것 보다도 앙상블 모델이 결과가 훨 좋았음.
subtrack 2 - Knowledge-grounded Dialogue Modeling
서브트랙 2를 살펴 보겠습니다. 각 단계별로 다음과 같은 특징이 있었습니다.

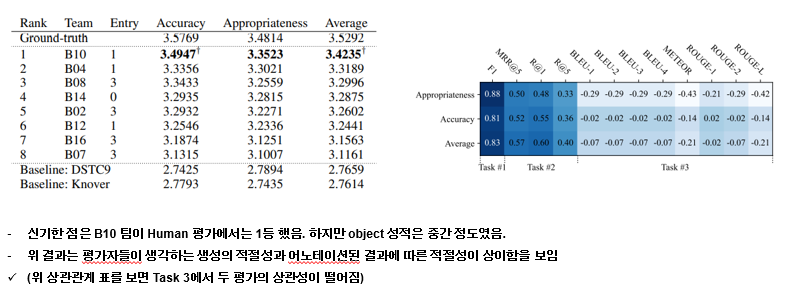
신기한 점은 기계적으로 자동 채점한 결과를 기반으로 상위 8팀에 대하여 생성된 결과를 human 평가를 진행했는데, objective 평가와 다르게 상관성이 떨어지는 점이 신기했습니다. 이는 spoken 스타일에 대한 답변이 실제 평가자들에게는 어색한 답변이다 라고 생각이 들었던 것 같습니다.
결론
1) 생성기반 DST 모델이 가장 좋았다.
2) 데이터 증강은 선택이 아닌 필수
3) 앙상블도 일부 성능향상에 기여함
4) 1등팀의 독특한 방식 <Speech simulator>가 중요했다!

댓글