본 논문은 acl 2021 메타러닝 워크샵에 공개된 논문입니다. 메타러닝 방식을 dst 분야에 처음으로 적용한 연구라고 생각하시면 됩니다.

논문은 dst 분야의 메타러닝 적용의 필요성에 대한 부분부터 시작하게 됩니다. 목적지향형 대화를 실제 세계에 맞게 구축하려면 정말 다양한 도메인들에 맞춤화 될 필요가 있습니다. 새로운 타겟 도메인에서의 대화시스템이 필요할 경우 많은 양의 도메인 specific한 어노테이션 된 데이터가 필요합니다.
이러한 작업은 굉장히 힘들다는것 아마 공감하실 것 같습니다!
Intro
이 문제를 해결하기 위해 이전 연구들에서는 기계독해 문제로 DST 문제를 변환하여 사용할 수 있는 외부 데이터를 통해 학습을 진행된 바 있습니다. 또한 특정 도메인 지식을 다른 도메인으로 transfer할 수 있도록 하는 연구도 진행되었는데 도메인 끼리 비슷한 맥락의 슬롯을 많이 공유하고 있다는 점 예를들어 레스토랑과 호텔과 같이 에서 아이디어를 냈다고 합니다. 이러한 연구가 진행되면서 zero shot에 대한 연구도 함께 각광을 받고 있습니다.

그래서 굉장히 빠르게 적응하되, 굉장히 적은 샘플로도 효율적인 성능을 내는 MAML과 reptile과 같은 방식들의 도입이 중요하게 되었습니다. Agnostic한 방식으로 어떠한 모델과 분야에도 최적화 방식의 메타러닝이 적용될 수 있기에 본 연구에서도 이러한 알고리즘으로 few shot learning for dst를 시도해보고자 했다고 이야기 합니다.
결론적으로는 dst에 메타러닝 방식을 적용한 첫번째 연구라고 이야기 하고 있습니다. 이전의 연구들의 초점은 새로운 task의 데이터가 적은 문제를 해결하기 위해 이미 구축되어있는 대규모 도메인 데이터들을 합쳐서 학습하고 적은 데이터라도 이용하여 파인튜닝을 하는 방식이었으나, 이는 도메인간의 지식전류가 비효율적이고, 새로운 도메인 데이터는 적은 와중에 어노테이션이 잘되있지 않을 수도 있다 그럼 성능이 매우 떨어진다 라고 이야기 합니다.

하지만 본 방식에서는 메타러닝을 통해 최적의 파라미터를 찾아 감으로써 파인튜닝 단계에서 최적의 파라미터로 초기화합니다. 우리는 서로 다른 도메인이 많은 것을 공유한다고 가정합니다. 하지만 서로 다른 복잡성을 가질 수 있습니다. 일부 도메인의 경우 더 쉬울 수 있습니다. 매우 적은 수의 예제를 사용하여 모델을 train 하는동안 많은 수의 gradient descent가 필요할 수 도 있다. 메타 러닝은 이러한 기울기 정보를 고려하여 도메인 간에 공유할 수 있습니다.
모든 도메인에 대한 공동 손실을 동시에 최소화하려는 초기화를 찾는 대신, 일부 (k< 5) 그레이디언트 단계에서 개별 도메인의 최적 매개변수에 도달할 수 있는 지점을 찾습니다. 실제로 5번 이하의 gradient steps를 통해 대부분 찾아지며, 비슷한 슬롯을 공유하는 도메인이 하나라도 있다면 빠르게 파라미터를 최적화 할 수 있습니다. (예를 들어 호텔&레스토랑 , 텍시&트레인)에서는 더욱 빠르게 파라미터 최적화가 이뤄집니다.
결과적으로 적은 데이터를 가지고도 쉽게 Fine tuning이 가능해집니다.
실제 이러한 알고리즘을 적용한다면 어떠한 개발자라도 새로운 도메인에 대한 4개-8개의 예시만 만들면 훌륭한 챗봇을 구현해 낼 수 있다고 합니다.

연구를 통해 기여한 점은 메타러닝을 dst에 적용함으로써 얻는 이점과 reptile을 dst에 적용한 d-reptile 알고리즘을 제안해서 dst 분야의 제로샷 퓨샷 러닝 카테고리에서 sota를 달성했다는 것 그리고 기존의 퓨샷 러닝 베이스라인 보다 최대 25%까지 성능향상을 보였다는 것 입니다.
Background
관련연구를 살펴 보겠습니다. 대화 시스템은 이렇게 네개의 세부 task로 나눌 수 있는데요 각각 다른 모델로 수행이 되지만 input이 들어와 output이 나오는 것은 다음과 같은 순서라고 생각하시면 될 것 같습니다.
가장 먼저 대화 이해 nlu, 들어온 대화의 엑트 슬롯을 추출하는 dst, 그리고 이렇게 추출된 값에 따라 적절한 조치를 판단할 수 있는 DP, 그리고 이러한 조건에 맞는 적절한 값을 생성하는 nlg 분야로 나뉘게 됩니다. 그 중에서도 DST는 유저와 시스템의 발화에서 모델이 알아야하는 값들에 대하여 도메인, slot, value를 추출하는 과정이라고 생각하시면 됩니다. 예를 들어 첫번째 유저 말에서 모델이 적절한 값을 내기 위해서는 싼 레스토랑을 원한다는 것과 도시 중심에 위치한 곳이라는 것을 알아야겠죠? 그래서 하단에 dialogue state형식으로 다음과 같이 추출됩니다.
모델 관련해서는 본 연구에서 기본 베이스 모델구조로 사용했던 starc에 대해 이야기하고 있습니다 기계 독해 분야를 dst에 적용하여 각각의 slot별로 해당하는 질문을 만들어 발화함께 sep 토큰으로 연결하여 bert에 넣는 구조인데 예를 들어 호텔도메인의 네임 슬롯이다 했을때 질문인 what-이 발화와 함께 들어가게 됩니다.
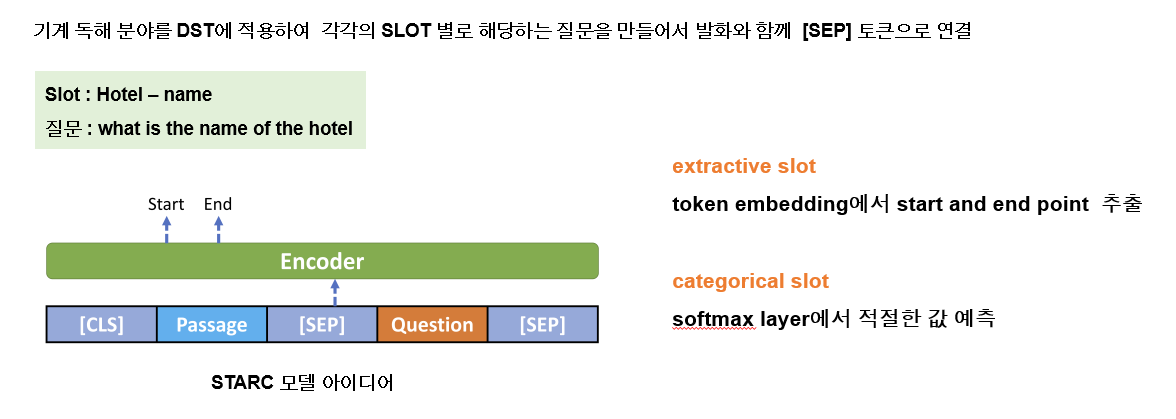
그리고 extractive slot과 카테고리컬 슬롯을 예측하는 방식도 조금 다른데 추출을 해야하는 값들은 토큰 임베딩 에서 start와 end point를 예측하여 span을 예측해 적절한 값을 추출하는 방식이되고, 카테고리컬 slot에서는 정해진 값 후보중에 softmax layer에서 나온 최종 값으로 예측한다 라고 할 수 있습니다.
Method
maml 방식에 대해 설명하면서 이차 도함수 문제로 reptile을 선택했다고 이야기 하고있습니다.
initializatio을 업데이트 하는 과정은 REPTILE과 같은데 아까 이야기 했듯이 간단하고 연산적인 부분에서 많은 이득을 가져서 선택했다고 합니다. 그럼에도 불구하고 업데이트 STEP을 거쳐가면서 초기화를 잘 진행해나간다고 합니다. 따라서 이러한 우수한 점을 DST문제에 적용시켰다 라고 이야기 하며 본 알고리즘의 목적은 Fine truning 단계에서 새로운 TASK 즉 새로운 도메인에 맞춤화된 새로운 최적화 파라미터를 찾는 것이라고 이야기 합니다.

노테이션은 다음과 같은데요 학습가능한 대규모 도메인w집합을 대문자 d라고 하고 각각의 요소들이 small d로 표현합니다. 이는 각각 도메인 이름 레스토랑 텍시 등이 되겠습니다. 그리고 pd는 이러한 도메인들이 가지고 있는 확률 분포 입니다. 그리고 m은 메타 파라미터를 가지는 어떠한 dst모델도 될 수 있습니다. small m은 task 배치사이즈로 한번 학습에서 몇개의 task를 같이 볼지 입니다. 본 알고리즘에서는 task가 각 도메인이라고 보시면됩니다 예를 들어서 m이 3이면 레스토랑 텍시 어트렉션 이렇게 3종류의 task가 함께 들어간다 생각하시면 됩니다.
그리고 a와 b는 각각 이너 아웃 루프의 러닝레이트고 k가 gradient step의 수입니다.

그래서 알고리즘을 정리해보자면 메타러너의 알고리즘을 랜덤으로 초기화 하고 기존에 구축되어 있는 도메인m개를 골라 즉 task m개를 배치화 하여 학습을 진행합니다. 러너는 메타러너의 파라미터를 각 도메인에 specific하게 초기화 하기 위해 이용합니다. 러너는 서포트 셋에 기반하여 파라미터가 업데이트 되고 최종적으로 메타러너의 파라미터가 업데이트 되는 순서입니다. 이너 루프에서 학습과정을 살펴보면 엠리스트와 비슷한 데이터셋으로 예를 들자면 이렇게 메타 트레인에서 5개의 데이터를 가지고 학습을 하고 각각 테스트를 거치면서 학습을 해나가고 이후 테스팅 단계에서는 아예 새로운 5개를 적용하여 성능을 평가하는 것입니다.

이것을 DST분야에 적용하면 전체적인 과정은 서포트셋에서의 뉴럴 넷을 거쳐 로스를 계산하고 벡프롭하여 업데이트를 진행하고 이렇게 생긴 각각의 task specific한 파라미터들이 다시 뉴럴렛을 통해 최종 쿼리셋과 함께 파라미터가 업데이트 되는 과정입니다.
따라서 처음에 랜덤으로 초기화된 파라미터가 뉴럴렛을 거치며 이렇게 서포트셋에서 최적화된 각각의 파라미터 들로 업데이트 됩니다.그래서 각각의 테스 별로 세타 1 세타 2 이렇게 탄생하게 되는 것 입니다.

그래서 처음에 초기화된 각각의 파라미터들이 task에 맞게 스페시픽 하게 파라미터들이 확률적 경사하강을 통해
업데이트 됩니다. 그 후에 쿼리셋을 이용하여 각각의 로스를 계산합니다. 그리고 이러한 로스를 더 하고 최종적으로 메타 파라미터를 업데이트 시킵니다
이러한 알고리즘의 우수성을 비교하기 위해 nft 알고리즘을 비교대상으로 선정했는데요 nft는 naive pre-training before fine-tuning의 약자로 모든 task에 대해 loss를 최소하는 방식으로 최적화를 진행하는 앞서 설명드린 multi task learning의 개념이라고 보시면 될 것 같습니다. 주요 특징은 기존 도메인과 유사한 task에서는 잘 작동하지만 기존 도메인의 최적화값과 new task의 최적화 값은 거리가 있으며 도메인이 다양해 질 수록 각각의 최적화된 파라미터와 멀어집니다. k-gradient descent steps를 통해 개별에 맞는 최적화를 찾아낸다는 부분에서 차이를 보인다라고 생각하시면됩니다.

도메인별 그레디언트 값을 비교해보면 레스토랑 같은 경우 기존의 도메인들과 비슷한 슬롯을 많이 공유하고 있기 때문에 더욱 작은 그레디언트 값을 가지고 있고, 텍시는 유니크한 슬롯이 많이 있기 때문에 보다 큰 그레디언트 값들을 가지고 있습니다. 그래서 새로운 도메인에 대하여 식당 도메인이 최적의 파라미터에 보다 가까운 지점에 도달 할 수 있습니다. 하지만 새로운 도메인이 호텔이냐 버스냐에 따라서는 그래디언트 값에 따라 다르게 최적화가 되는데 호텔은 레스토랑과 비슷한 지점에 그리고 버스는 택시와 비슷한 지점에서 최적화 파라미터를 찾게 됩니다.

데이터셋은 총 3가지를 사용했는데 기본으로 멀티 오즈와 dstc 8데이터를 사용했습니다. 그리고 베이스 모델외에 기계독해 데이터셋을 활용하여 추가 프리트레인 한 모델을 만들기도 했는데 이는 베이스모델과 구분을 위해 -rc를 덧붙였다는 것에 차이를 보이고 있습니다.

🦄 참고논문 링크 : https://arxiv.org/abs/2101.06779
'AI Researcher가 될끄야! > 메타러닝' 카테고리의 다른 글
| [논문 리뷰] Few Shot Dialogue State Tracking using Meta-learning (PART 2 Result, additional Analysis) (0) | 2022.01.17 |
|---|---|
| Automatic deep learning with meta learner (0) | 2022.01.17 |

댓글