Result
평가는 일반적으로 dst 분야는 jga를 사용하는데 여기서는 none값으로 분류된 slot 말고 실제 값이 매칭되는 activate한 slot에 대해서만 정확도를 평가했다고 합니다. 그리고 모델은 starc 모델 구조로 두가지 알고리즘을 비교했고, 기본적으로 워드 임베딩은 로버타 라지 모델, 그리고 옵티마이저는 아담을 사용했습니다.

결과적으로 32개의 대화 셋 데이터만을 가진 로우 리소스에서 dst가 잘된다. 여기 정확도를 보시면 동일한 데이터 양으로 기존의 dst 모델을 학습시켰을 때는 다음과 같은 성능인데 본 모델은 가장 낮은 도메인에서도 32를 넘습니다.
이는 메타러닝에 의해 선택된 초기화가 그레이디언트 단계 측면에서 대상 도메인의 최적 매개 변수에 더 가깝기 때문에 데이터가 매우 적을 때 더 잘 수행된다는 가설을 검증합니다. 그러나 미세 조정 데이터가 1000개가 넘었을 때는임의의 초기화도 대상 도메인에 대한 최적의 매개 변수에 도달할 수 있다. 그래서 아래에서 하나씩 설명한 바와 같이 서로 다른 도메인, 데이터 세트 및 모델에 걸쳐 제한된 데이터에서 D-REPTIL의 장점을 관찰한다. 먼저 도메인별 알고리즘에 따른 성능차이, 그리고 모델에 대한 차이를 봅니다.
그리고 모델에 대한 차이는 여기서 추출에 해당하는 슬롯과 카테코리컬한 값을 가지는 슬롯에 대하여 따로 학습시킨 모델에 대한 각각의 성능을 비교합니다.
그리고 마지막으로 본 효과가 멀티오즈에만 국한되지 않음을 보이기 위해 데이터셋에 대해 성능을 비교합니다.
먼저 도메인에 따른 성능을 비교해 보겠습니다. 총 5가지의 도메인에 대하여 실험을 진행하였습니다. 호텔, 레스토랑, 트레인, 어트렉션, 택시입니다. 그래프에 대해 설명해 보자면 첫번째 호텔 도메인을 예로 들면 호텔 도메인을 타켓 도메인으로 삼고 나머지도메인을 트레인에 사용했다고 생각 하시면 됩니다. 그리고 직선 형태의 그래프가 Dreptile 방식으로 최적화를 하고 점선이 NFT 방식 입니다. 그리고 빨강과 파랑 초록은 각각 로버타 임베딩으로 starc 모델 즉 베이스 모델, 그리고 기계독해 데이터셋으로 추가 프리트레인 시킨 rc 모델 그리고 아무것도 프리트레인 하지 않은 초록색 모델입니다. 따라서 매우 안좋은 성능을 보이고 있습니다 엑스 축은 학습시킨 데이터의 양을 나타냅니다. 이렇게 봤을 때 레스토랑 도메인에서 D-reptile 모델이 NFT모델보다 25퍼 정도 좋은 성능을 보입니다
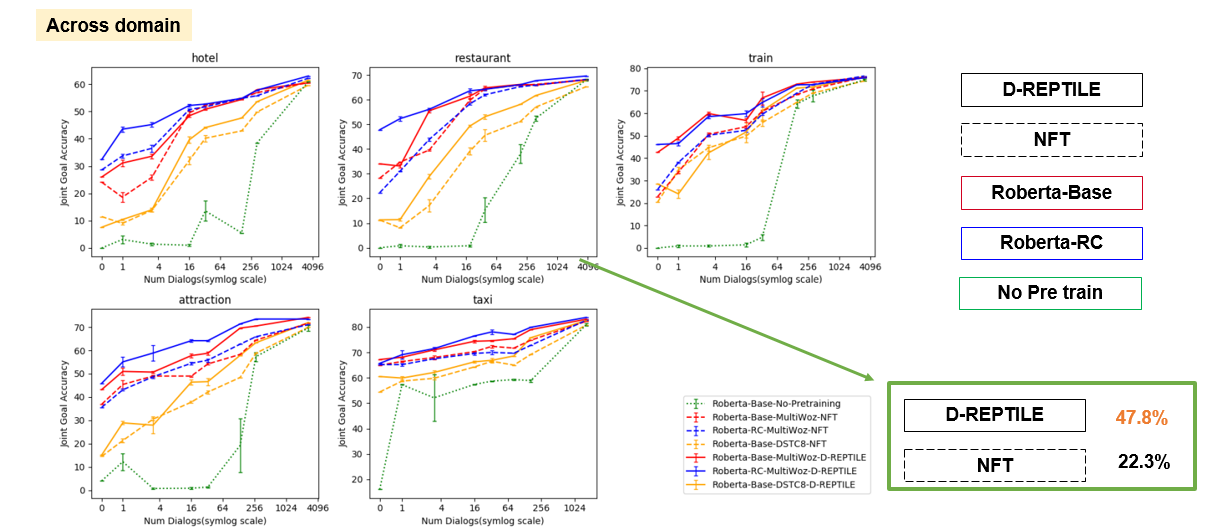

데이터셋에 따른 이점도 이야기 해보겠습니다. 실제로 여기선 멀티오즈 말고도 dstc8데이터셋을 함께 사용했습니다. 그림을 보시면 오렌지 라인이 dstc8 데이터셋을 트레인 도메인으로 타겟도메인을 멀티오즈로 부터 활용하여 학습을 시킨 그래프 입니다. 결과를 보면 빨강과 파랑보단 성능이 떨어짐을 알 수 있습니다. 빨강과 파랑은 당연히 멀티 오즈의 타겟도메인 외로 학습을 시킨 그래프입니다.

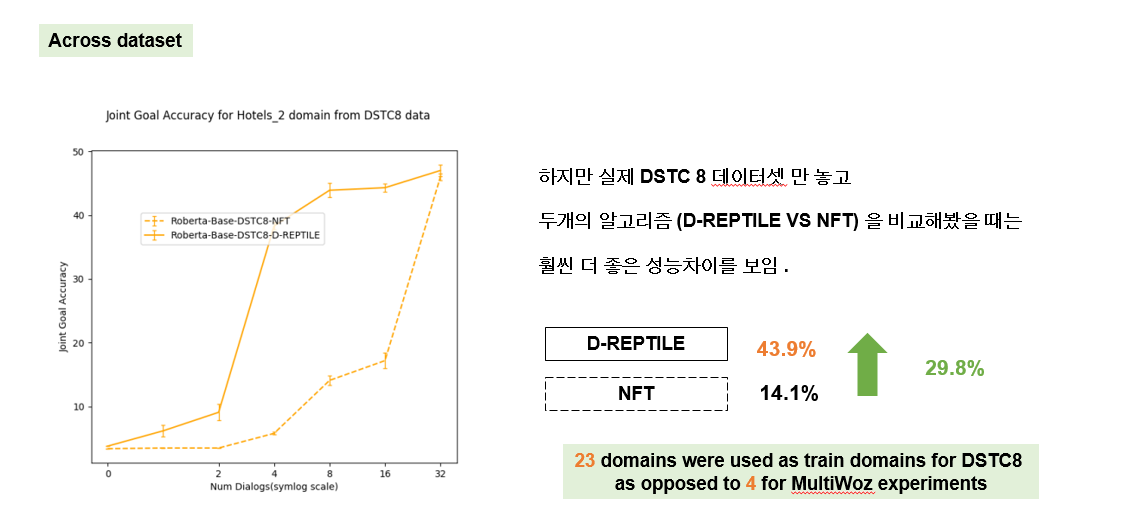
그래서 별도로 dstc 8 데이터만 가지고 두가지 알고리즘을 실험해 봤을 때 오히려 멀티오즈 보다 좋았습니다. dreptile 알고리즘이 nft 모다 29.8퍼센트나 높았습니다. 데이터셋에 차이를 보면 dstc8이 24개의 도메인으로 23개 도메인을 트레인에 사용했고 멀티오즈는 5개로 4개를 트레인에 사용했다는 점이 다릅니다. 이는 학습해야하는 테스크의 갯수가 많아도 잘 작동된다는 것을 알 수 있습니다

놀랍게도, 메타 데이터 초기화는 더 빨리 적응할 뿐만 아니라 시작하기에 더 좋다. 제로샷 성능도 개선되었습니다. NFT와의 비교 외에도 MultiWoz 2.0 데이터 세트에 대한 기존 dst 모델보다 개선된 점을 보여줬습니다다. 또한 D-REPTILE은 모델 애그노스틱하므로 새로운 미지의 도메인에 대한 모든 기본 모델에 대해 JGA를 개선할 수 있는 기능이 있다는 것 입니다.
추가적인 분석
좌측은 모든 도메인에서 자주 등장하는 슬롯기준 성능을 측정한 표이고 우측은 각 도메인에서 유니크한 슬롯에 대해 성능을 측정한 것 입니다. 예를 들어 day는 호텔 도메인에서도 레스토랑에서도 트레인에서도 등장하고 반대로 푸드는 레스토랑 도메인에서만 등장합니다. 너무 많아서 대충의 형태만 보시면될 것 같고 특징을 정리해 보겠습니다.
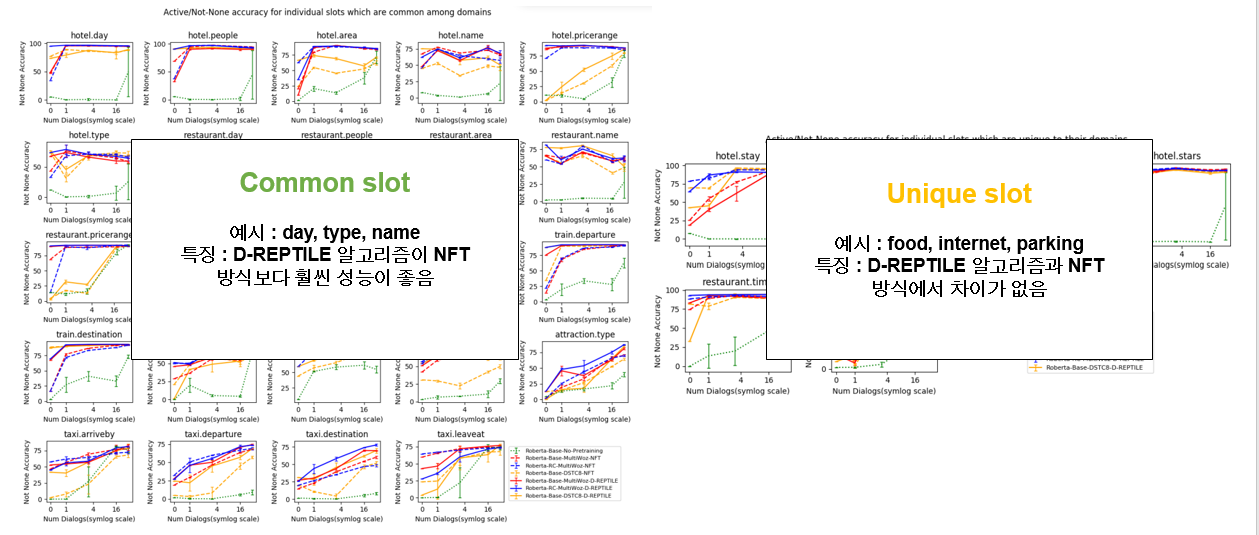
자주 등장하는 슬롯에서는 d-reptile알고리즘 방식이 nft 방식보다 훨씬 좋지만 유니크 슬롯에서는 어떤것이 좋다라고 말하기가 애매하다라고 하고 있습니다. 유니크 슬롯은 기존의 도메인에서 얻는 효과각 미미하다고 볼 수 있습니다. 하지만 커먼 슬롯같은경우는 많은 영향을 받고, dreptile방식이 훨씬 좋다고 정리할 수 있습니다.
- 하이퍼파라미터

도메인의 pD(.)를 선택하는 것이 해당 도메인의 교육 데이터 세트 크기에 비례하여 도움이 된다는 것을 발견했습니다 여기 그래프 기준으로 하늘색과 빨간색의 차이라고 보시면됩니다. k는 동일하고 정규분포로 했느냐 비례하게 했냐의 차이인데 비례하게한 빨강색 선이 하늘색 보다 조금 더 좋은 성능을 보이고 있습니다.. 이는 서로 다른 열차 도메인 간의 데이터 불균형의 경우, 알고리즘이 자원이 풍부한 도메인의 모든 데이터를 더 자주 선택하여 더 잘 일반화할 수 있기 때문이다. 또한 k는 gradient step의수를 의미하는데 너무 적거나 너무 많으면 성능에 악영향을 미치고 5가 가장 적절했다. 그래서 모든 실험은 5로 진행했다고 이야기 합니다.
의문점
그래서 결론은 다음과 같습니다. 몇가지의 의문점은 정확하게 few shot이라는 것을 몇개정도의 데이터를 의미할 것인지, 현재 실험결과를 보면 새로운 테스크의 유니크 슬롯은 성능이 미미한데 실제세계에서는 각기 다른 분야의 전문 용어라던지 분야가 있을텐데 이런 것에 관련된 few shot은 어떻게 해결할지에 대한 의문은 남습니다
'AI Researcher가 될끄야! > 메타러닝' 카테고리의 다른 글
| [논문 리뷰] Few Shot Dialogue State Tracking using Meta-learning (PART 1 intro, background, method) (0) | 2022.01.17 |
|---|---|
| Automatic deep learning with meta learner (0) | 2022.01.17 |

댓글