제가 오늘 리뷰할 논문은 작년 DSTC 10 TRACK 2에서 두 서브 트랙에서 모두 우승했던 방식을 서술한 논문입니다. AAAI에 Accept된 논문입니다.

🦄 INTRODUCTION
기존 Task-oriented dialogue system의 문제점은 대화 데이터를 모으고, 어노테이션 하는데 힘들고, 질이 좋지 못하다는 문제가 있었으며, 많은 가상 에이전트들이 음성대화를 기반으로 작동하지만 실제 학습 데이터는 written 형식으로 되어 있어 실질적인 대화 스타일을 담지 못한다는 문제가 있었습니다. 단어 level 에서 기존의 데이터 셋을 작성하는 방식을 사용하기도 하였으나 이는 대화의 다양성이나 유연성을 보장하지 못합니다.

그래서 본 팀은 두가지 해결방안을 제시하고 있습니다. 대화 데이터셋 자체를 증강할 수 있는 방식과 음성대화 스타일을 담기위한 Spoken Conversation Simulator를 만드는 방식입니다. 이때 DSTC 10은 두 가지 트랙으로 나뉘었는데 첫번째 트랙은 다중 도메인에서의 대화상태추적 이고 두번째는 지식 기반 대화모델링 입니다. 이 대회의 핵심 키는 INPUT 자체에 ASR 에러를 포함하고 있다는 것입니다.
이러한 상황 속에서 다중 도메인에서 적절하게 DST를 진행하고, 지식접근이 필요한 턴을 구분하여 지식 기반 대화를 하는 TASK로 나뉘게 되는 것 입니다.
✍ Task-oriented Dialogue Data Augmentation
-Dialogue Enrichment
가장 먼저 학습 시키는 대화 데이터셋 자체를 증강시키기 위해 Dialogue Enrichment 라는 방식을 제안하고 있습니다. 이 방식은 두가지 방법으로 나뉘게 되는데 온톨로지 베이스로 증강을 진행하는 방식과 패턴 베이스로 증강을 하는 방식입니다.

먼저 온톨로지 베이스 방식은 WOZ나 MULTIWOZ의 형식을 따르는 기존의 하이 퀄리티 데이터셋을 활용하여 융합하는 방식입니다. 그림 처럼 온톨로지 A와 B에서 FOOD 와 AREA 부분에 해당하는 VALUE를 서로 SWITCH하는 방식으로 데이터를 증강합니다. 이는 하이퀄리티 데이터셋의 구조는 파괴하지 않으면서 효율적으로 증강이 가능하다는 장점이 있습니다.
패턴 베이스 증강 방식은 온톨로지 방식의 단점을 보안합니다. 온톨로지 방식은 높은 퀄리티의 대화 구조상에서 슬롯 교환 방식으로 증강을 하여서 고정된 대화 구조를 가지고 있다는 단점이 있습니다.
따라서 본 방식에서는 데이터셋을 Dialogue act마다 각각의 패턴 즉 템플릿 형식으로 만들어서 빈칸을 뚫어 놓고 접두사 접미사 형태로 나누어서 엔티티 앞뒤로 들어 갈 수 있는 슬롯 표현을 셀렉션 하여 value를 채우는 형식으로 증강을 진행하였습니다. 엔티티 앞에는 대부분 형용사 위주의 표현이 뒤에는 추가 설명이나 조건을 부연하는 슬롯이 올 수 있도록 패턴은 구성되었다고 합니다.

단계별로 좀 더 살펴 보면 dialogue action을 transition하는 부분은 markov chain 방식으로 transition matrix를 활용하는 방식으로 이전 act에 따라 다음 act가 제한되는 형식으로 구성욉니다. 또한 transition 확률은 dialogue act의 co-occurrence의 빈도를 정규화 한 것으로 계산됩니다. 그리고 두번째 단계에서 가능한 후보 리스트에서 랜덤으로 패턴을 추출하고 최종적으로 데이터 베이스에서 거기 에 맞는 슬롯 벨류를 채우게 됩니다. 이 과정에서 어노테이션 부분에도 자동적으로 어노테이션이 되게 됩니다.
이러한 전략은 기존의 public 데이터를 최대한 활용하면서도 대화의 다양성을 향상 시킬 수 있고, 무한하게 task-oriented 대화 셋을 생성해 나갈 수 있습니다.
- Spoken Conversation Simulator
ASR결과는 DST 진행 시 많은 에러를 발생시킵니다. 따라서 본 논문에서는 언어적인 관점에서 언어적 특성을 반영한 오류를 시뮬레이트 하는 시뮬레이터 방식을 적용하였고, 각각 3가지 방식으로 시뮬레이터를 구성하였습니다.
첫번째는 Automatic Speech Recognition 방식입니다. tts를 활용한 방식으로 구글 tts로 텍스트를 음성데이터로 변환하고 다시 인식하여 인식오류를 포함 데이터로 변환합니다. 이러한 데이터 들은 워드레벨이나 문단 단계에서 비슷한 것으로 대체되는 경우가 있음 예시를 보시면 ‘moderately’가 ‘modernly’로 바뀌는 것을 보실 수 있습니다.

written data와 spoken 데이터의 가장 큰 차이는 유창성에 있습니다. 텍스트 데이터는 실수 없이 말끔히 쓰여진 데이터이지만 실제 발화에서 사람은 많은 실수를 하기 때문입니다. Speech Disfluency simulator 입니다. Disfluency라는 것은 말더듬 이라는 뜻인데, 이처럼 발화 사이사이의 말 실수 부분입니다. 여기서는 4가지 유형을 추가하였고, 다음과 같습니다. 예는 다음과 같은데 음음 거리는 것과 아이를 반복한다 던지의 사례입니다.


ASR 에러는 대부분 비슷한 발음 때문에 일어나기 때문에 phoneme-level에서 오류를 발생시킬 수 있는 것으로 5가지 유형으로 오류를 만들 수 있도록 했습니다. 예시는 다음과 같습니다. 대체 되는 경우는 looking에서 k가 g로 변경되는 경우 등이 있습니다.


🌮 Task-oriented Dialogue Modeling & Experiments

다음은 학습 시킨 모델입니다. 거의 두 모델 다 구조적인 변화는 거의 없이 기존의 모델을 가져와 학습하고 앙상블 하는 방식이 었는데, subtrack1에서는 트랜스포머 기반의 모델로 파인튜닝을 하였는데, 특이한 점은 모든 dialogue history를 인풋으로 하지 않고 window size n만큼의 이전 히스토리와 이전 dialogue state , 수식에서 B 부분을 삽입하였습니다. Subtrack 2 에서는 3가지 모델이 사용되었는데 거의 생성기반 모델인 plato2를 파인튜닝 하였습니다. 디텍션 부분에서는 이진 분류 문제로 binary cross-entropy loss를 최소화 하는 방향으로 학습을 진행합니다. 3)에서 y는 여기는 실제 라벨 값으로 지식 접근이 필요한지 안한지의 여부입니다.
다음은 selection 부분입니다. 적절한 지식을 찾기 위해 Negatives Enhanced Knowledge Selection 방식을 사용했는데 여기서 negatives sampling 방식은 현재 집중하고 있는 주변 단어가 '고양이', '귀여운'이라고 해봅시다. 여기에 '돈가스', '컴퓨터', '회의실'과 같은 단어 집합에서 무작위로 선택된 주변 단어가 아닌 단어들을 일부 가져옵니다. 이렇게 하나의 중심 단어에 대해서 전체 단어 집합보다 훨씬 작은 단어 집합을 만들어놓고 마지막 단계를 이진 분류 문제로 변환합니다. 주변 단어들을 긍정(positive), 랜덤으로 샘플링 된 단어들을 부정(negative)으로 레이블링한다면 이진 분류 문제를 위한 데이터셋이 됩니다. 이는 기존의 단어 집합의 크기만큼의 선택지를 두고 다중 클래스 분류 문제를 보다 연산량이 줄어듭니다. 그래서 여기서는 5가지 척도의 부정 샘플을 만들어 학습을 진행했는데 각 방식은 다음과 같습니다.

마지막으로 생성은 bi-directional attention을 활용하여 문맥과 지식 묶음 사이에 언어 이해도를 높이고 auto-regressive 방식으로 답을 생성합니다.
본 논문에서 제안한 Negatives Enhanced Knowledge Selection 방식은 현재의 대화 문맥과 지식 db에서 관계성이 잇는 것을 추출하는 것을 목표로 하는데 각 긍정 샘플마다 5개 척도의 부정 샘플을 만들어 학습 시켜 이것은 결국 각 집합을 구분하는 이진 분류 문제로 변환되어 학습이 훨씬 편합니다.
😎 그래서 결과는 ㅎ?
- Track 2의 Subtrack1에서의 결과 1등!

- Track 2의 Subtrack2에서의 결과 1등!
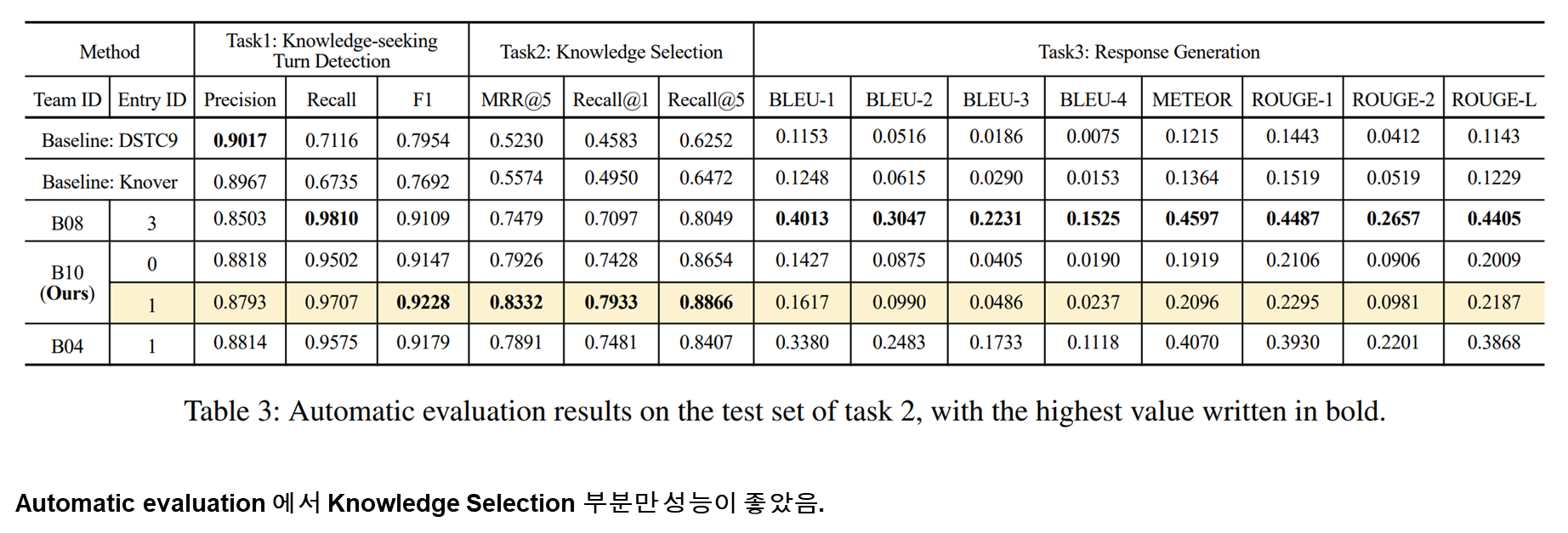
여러가지 실제 데이터를 제공하고 있는데 asr 오류를 포함하고 있어도 적절하게 dst가 잘되고 있음을 알 수 있음

'AI Researcher가 될끄야! > 대화 시스템' 카테고리의 다른 글
| [논문 리뷰] PLATO-2: Towards Building an Open-Domain Chatbot viaCurriculum Learning (0) | 2022.03.25 |
|---|---|
| [논문 리뷰]심층 신경망 기반 대화 처리 기술 동향 (0) | 2022.02.16 |
| [논문 리뷰] Learning knowledge bases with parameters for task-oriented dialogue system (0) | 2022.02.11 |
| Convlab2 - 대화 시스템 오픈 프레임워크를 소개합니다! (0) | 2022.02.11 |




댓글