오늘 소개할 논문은 ACL 2021에서 공개 되었고, DSTC9부터 10까지 휩쓸었던 PLATO2 모델을 소개해드리도록하겠습니다.
✅ 논문링크 : https://arxiv.org/abs/2006.16779
💚Abstract
핵심적인 내용은 전통적 open-domain 학습방식에서 일대일 맵핑 방식 뿐만 아니라 일대다 맵핑을 적용하였고, 적절한 응답을 고르는 절차를 두단계로 나누는 curriculum learning을 도입했다는 것 입니다. 첫번째 단계는 Coarse-grained generation model로 일대일 맵핑방식을 활용하여 학습을 하고, 두번째 단게에서는 fine-grained 모델로 latent variable을 활용하는 방식입니다. 본 모델은 영어와 중국어 두 가지 언어로 각각 학습하였습니다.
- open domain chat 뭐가 문제야?
현재 open domain에서의 동향과 문제점을 알아보도록 하겠습니다.
task agnostic한 Pre-train모델이 좋은 성능을 보이고 있고, 레딧 코멘트를 활용하여 응답 생성을 학습한 GPT2나 DialoGPT등이 있습니다. 사람 같은 대화 생성을 목적으로 파라미터를 크게 늘린 Meena와 해로운 toxic과 bias를 줄이기 위해 Blender 모델도 나왔습니다. 정말 인간적인 대화 스킬을 학습하기 위해 Blender 모델은 시도한 바 있습니다.
그리고 일대다 맵핑으로 학습을 시도한 plato1이 나왔고, ONE-TO-MANY 맵핑 방식의 학습은 오픈 도메인 대화 생성에 중요한 역할을 한다는 것이 이전 연구에서 밝혀진바 있습니다. 또한 Discrete한 latent variable 을 활용해 대화 생성 퀄리티를 높이려는 시도가 있었으나, 스케일을 높일 수록 학습이 불안정하고 비효율적인 부분이 있어 일대다 방식을 적용하기 힘들어, PLATO2는 새롭게 Curriculum learning 방식을 도입하였습니다.
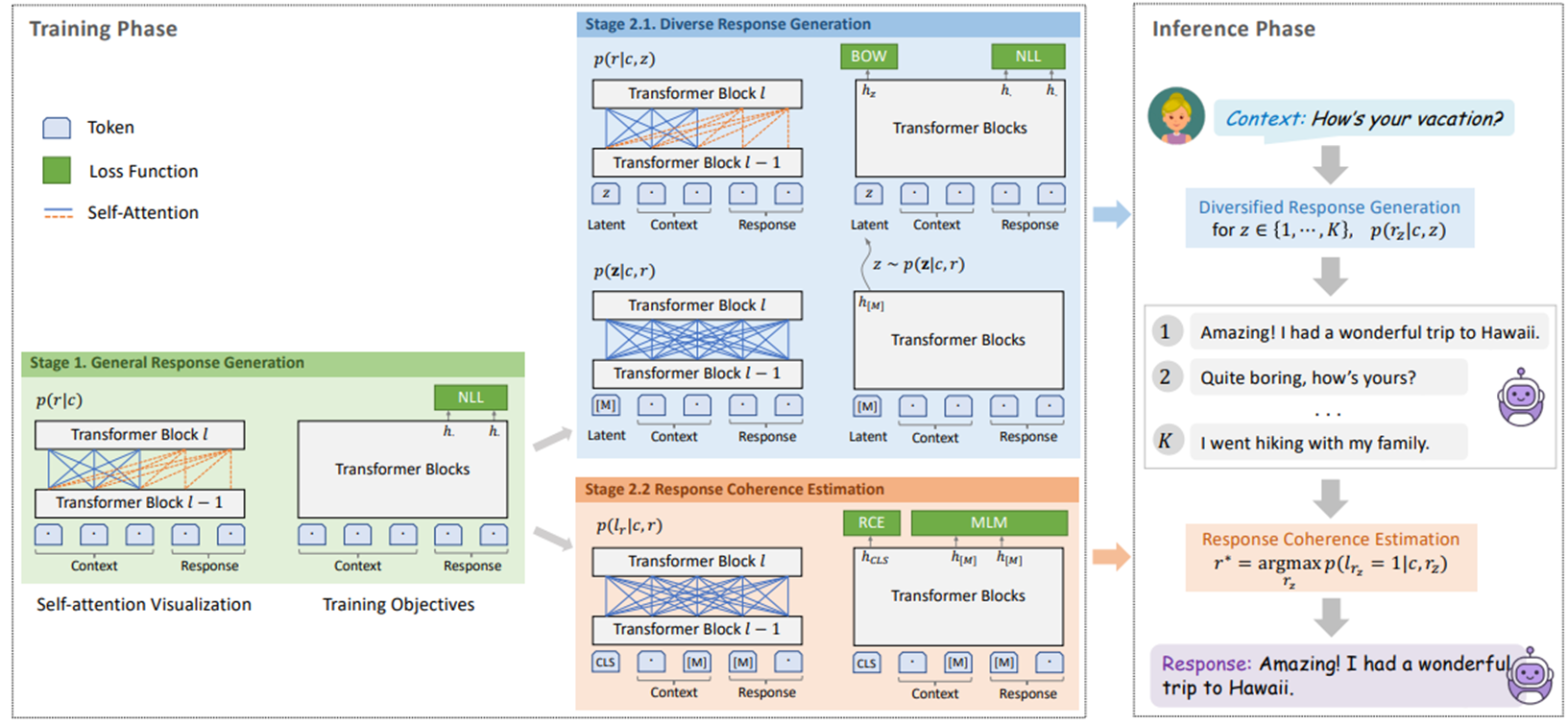
첫 단계에서는 오픈 도메인 대화에서는 원투매니 형식으로 정답에 해당하는 대답이 많을 수 있는데 전통적인 방식에서는 일대일 매핑을 하기 때문에 지루하거나 일반적인 답변을 하는 경우가 많습니다. 하지만 이 방식은 전통적인 패턴을 잘 잡아내고 안정적이고 보다 정확한 답변을 생성할 수 있습니다. 따라서 plato2는 일대일 매핑 방식으로 첫번째 coarse-grained baseline model을 학습시킵니다.(위의 그림을 참조해주세요)
두번쨰 stage에서는 generation 모델과 evaluation 모델로 나뉘게 됩니다. 핵심적으로는 latent variable을 활용하여 one-to-many mapping방식을 활용하며 가장 적절한 대답을 생성하기 위해 평가 모델은 양방향 conhernce을 대화 contex와 response간에 추정하게 됩니다. 이전 플라토 모델과 다르게 fine grained 생성, 평가 모델이 합쳐 짐으로써 보다 적절하게 task에 모델이 집중할 수 있도록 했습니다.
따라서 PLATO의 문제를 해결하여 모델 사이즈를 안정적으로 늘리고 task-oriented 대화에서도 성능이 좋음을 dstc9에서 증명했다라고 합니다. 정리하자면 모델사이즈는 다음과 같고, 언어는 두가지 언어로 구성되어 당시 sota를 달성하던 meena와 blender보다 좋은 성능을 냈다 라고 이야기합니다.
🧡Methodology
그 방식에대하여 이제 세부적으로 살펴보도록 하겠습니다. plato2 모델은 pre-normalization된 트랜스포머 블럭들을 기본 backbone으로 하고 있으며, 기존 Seq2Seq모델과 다르게 인코더 디코더 구조로 나눠져 있지 않습니다. 플라토2는 기존의 unified network 구조를 flexible attention mechanism을 통해 유지 합니다. 이 network에서 양방향 cotext encoding절차와 단방향 응답생성을 위한 network가 공유됩니다. PLATO2 모델이 KNOVER 프레임워크에의 세번째 Task 생성을 위한 단계에서는 앞단에 knowledge가 함께 추가됩니다.

첫번째 Coarse-grained generation model입니다. 문맥 조건이 주어지면 하나의 발화에도 다양한 답변이 있을 수 있습니다. 전통적인 대화적 관점에서는 이것을 일대일 매핑를 통해 학습을 시켰습니다. 하지만 generic하고 dull한 응답을 생성하는데, 반면 답변 생성에서의 general한 특징은 잘 잡아냅니다. 따라서 이 방식을 차용하여 일대일 매핑으로 coarse-grained 모델을 학습합니다.

학습 방식을 보다 세부적으로 살펴보면 학습데이터에서 contex와 response가 주워졌을 때 nll loss를 최소화 하는 방향으로 학습이 진행되는데 이때 대문자 T는 target response의 길이이고, 알티는 이전 생성된 단어들을 의미합니다. 떄문에 응답 생성 부분에서는 단방향 디코딩 프로세스가 진행됩니다. 그림에서 오렌지색 점선에 해당됩니다. 각각의 토큰은 오로지 이전의 것에만 영향을 받습니다. 그림에서 오렌지 점선을 의미합니다. 이와 같이 문맥 해석과 nlu를 위해서 파란색 선처럼 bi-directional attention이 가해지게 됩니다.
두번째 단계로 diverse한 응답을 생성하기 위한 단계입니다. 이 단계는 generation모델과 evaluation 모델로 나뉜다고 말씀드렸는데요, 먼저 generation 모델입니다.
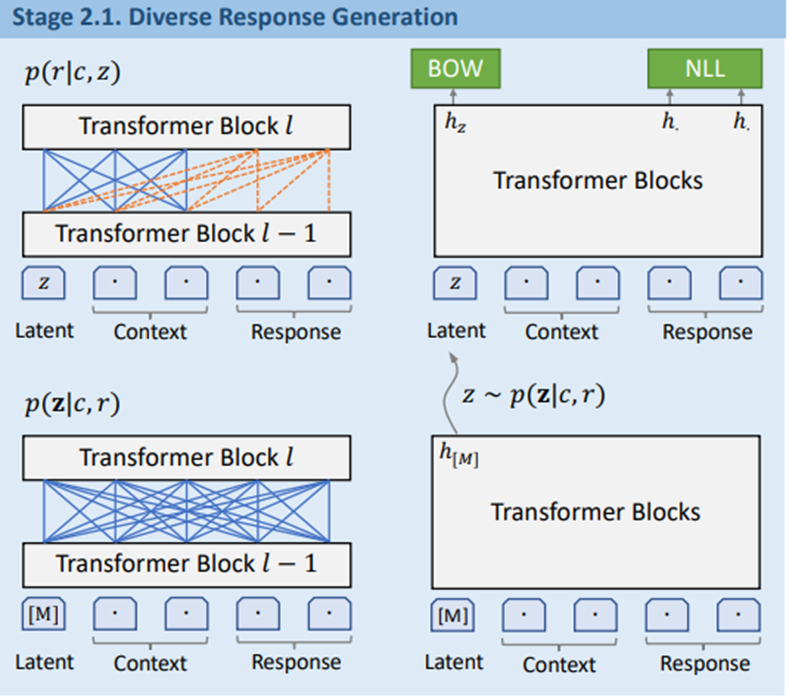
coarse-grained 베이스라인 모델의 결과로 warm start를 할 수 있는 환경에서 더욱 나아가 일대다 맵핑을 통해 학습을 전개합니다. 이전의 PLATO모델과 같이 discrete latent variable z를 사용합니다. z는 k-way categorical variabl로 정의되며 각각의 값들은 응답속에 특정 latent speech act와 일치합니다. 모델은 가장 먼저 학습 sample에서 latent act distribution을 추정합니다. 샘플링된 latent variable을 통해 응답을 생성하는데 이는 두가지 세부 task로 나눌 수 있습니다. 응답을 생성하는 부분, latent act를 인식하는 부분입니다. 이 두가지 테스크는 network를 공유하면서 함께 학습됩니다. 먼저 응답생성을 위한 nll loss의 수식은 다음과 같습니다.

여기서 z는 주어진 문맥c와 답변 r에서 뽑혀진 z latent act입니다. 샘플링은 구별이 힘들기에 Gumbel-softmax 방식으로 추정을 했으며, latent value들의 posterior distribution은 latent act recognition으로 추정이 되었습니다. 식은 3번과 같습니다. 여기서 hm은 special mask tokem [M]의 final hidden state 값입니다. W와 b는 fully connected weight matrix입니다.
다음은 discreate한 latent variable의 학습과정 촉진을 위해 bag-of-words(BOW) loss 부분입니다. V는 전체 Vocabulary를 나타내며, 함수 f는 타겟 답변의 단어를 non-autoregressive 한 방식으로 예측합니다.

5번 수식을 보시면 hz는 latent variable의 finalhidden state 값입니다. frt는 단어 rt로 추정된 확률입니다. nll loss와 비교를 해보았을 때는 bow loss가 단어 순서보다 target response에대한 global information을 잘 캡쳐하기 때문이라고 이야기 합니다. 따라서 정리하자면 생성 모델은 다양한 답변을 생성때의 nll로스와 latent variable을 위한 bow로스를 합친것을 최소화하며 학습이 진행됩니다.

다음은 두번째 단계에서 평가 모델입니다. 각기 다른 latent variable을 할당함으로써 fine-grained 모델은 높은 퀄리티, 다양한 답변을 생성할 수 있습니다.

따라서 이러한 후보군들 중에서 적절한 답변을 선택하기 위해서는 쉬운 방법으로는 문맥에서의 z변수 추출 확률 그리고 문맥과 z 변수에서 r이 뽑힐 확률을 이용해 순위를 맥일 수 있습니다. 하지만 잘 알려져 있듯이 문맥 속에서 z 변수에 대한 사전 분포를 예측하기는 힘들고, 정규 분포는 좋은 근사치는 아닙니다. 따라서 여기서는 evaluation모델을 적용하여 답변과 문맥의 coherence를 추정합니다. loss는 다음과 같습니다.

여기서 coherence과 관련된 라벨로 positive,negative sample을 나누어 줬습니다. 먼저 positive는 주어진 문맥과 답변속에서 일치하는 sample로 라벨 1이 반대로 negative sample은 코퍼스에서 랜덤하게 주어지고 라벨 0으로 라벨링 되었습니다.

추가적으로 적절한 응답을 고름에 있어서 전통적인 방식을 살펴 보면 두가지 방식이 대부분인데 첫째로 length-average log likelihood로써 forward response generation 확률을 이용합니다. 이 방식은 안정적이고 generic한 답변을 잘 생성하는데 maximum likely hood의 성질 때문입니다. 두번째 방식은 maximum mutual information 방식인데 backward context recovery 확률을 통해 결정됩니다. 이 방식은 굉장히 답변이 카피 한것 처럼 overlap됩니다. 반대로 이 모델에서 제시하는 discriminative 한 방식은 양방향 information flow를 context와 response간에 공유가되기 때문에 보다 효과적인 답변을 생성할 수 있습니다.
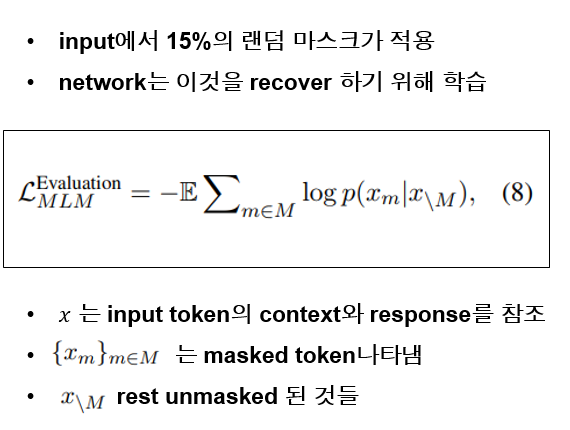
분포된 representation을 유지하기 위해 mlm 모델도 적용이 되었는데, 15퍼센트의 input token이 랜덤으로 마스크되고 network는 그것을 회복시키기 위해 학습이 진행됩니다. loss는 다음과 같습니다.x는 input token의 context와 response를 나타냅니다.
정리하자면 evaluation model은 rce 와 mlm 의 loss를 최소화하는 방향으로 학습합니다.

💜Experiments
-Training Data
이제 직접적인 실험과 타 모델들과 비교한 내역을 정리해 보도록 하겠습니다.
영어, 중국어 모델로 각각 학습을 진행했으며, sns데이터를 활용하여 학습을 했습니다.
영어 버전은 다음과 같으며, 중국 버전도 다음과 같아 영어 최종적으로 684 m, 중국어 1.2b 데이터를 모았습니다.
-비교 모델들
다음은 plato2와 비교대상이 되었던 5가지 모델에 대한 설명입니다.

그리고 적절한 성능비교를 위해 PLATO2 모델도 비교대상 모델 사이즈에 맞추어 각각 다르게 학습을 진행했고, Blender와 비교했던 모델이 standard 버전으로 되어있습니다.

-평가지표
다음은 평가 지표입니다. automatic 방식과 human 평가가 동시에 진행되었습니다.
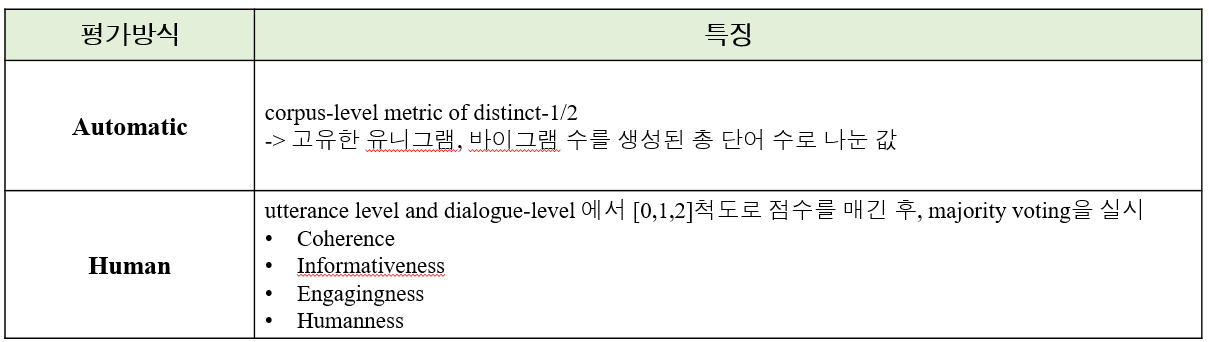
automatic 방식에서는 코퍼스 전체 레벨에서 distinct-1/2 방식이 사용됬는데 이것은 고유한 유니그램, 바이그램 수를 생성된 총 단어 수로 나눈 값 입니다. human 평가에서는 발화 level과 대화 level에서 0-2 척도로 4가지 기준 평가가 있었습니다. 가장 먼저 coherence는 발화 레벨에서 응답이 이전의 문맥과 연관성이 있는지에 대하여 측정합니다. informativeness도 발화 수준에서 응답이 정보적인지를 평가합니다. 그리고 engagingness는 대화 수준에서 대화를 계속해서 이어나고 싶은지 즉, 대화가 매끄럽고 자연스러운지를 평가합니다. 마지막으로 humanness는 대화 수준에서 사람같은지 아닌지를 평가합니다.
-평가방식
평가지표 말고 평가방식에 대해서도 짚고 갈 필요가 있는데요 실험을 위해 2가지 평가방식이 적용됬습니다. 먼저 self-chat 입니다. 대화 시스템을 평가하기 위해 많이 사용되는 방식인데요 모델이 사용자와 에이전트 역할을 둘다 수행하며 끼리끼리 대화하는 방식입니다. 저렴하고 효율적인 data collection이 가능합니다. 하지만 몇가지 주의점이 있는데, 단순히 hi와 같은 인사로 대화를 시작하면 모델은 shallow topic만 다루다 짧은 대화로 끝나게 됩니다. 따라서 미리 질문 목록을 selection 즉 topic을 선정하여 해당 질문으로 대화를 시작하게 됩니다. 200개의 질문 목록에서 대화가 시작되었고, 10턴으로 구성했다고 합니다. automatic에서는 200 chat, 이중 50개의 대화가 랜덤으로 추출되서 사람에게 평가되었다고 합니다.
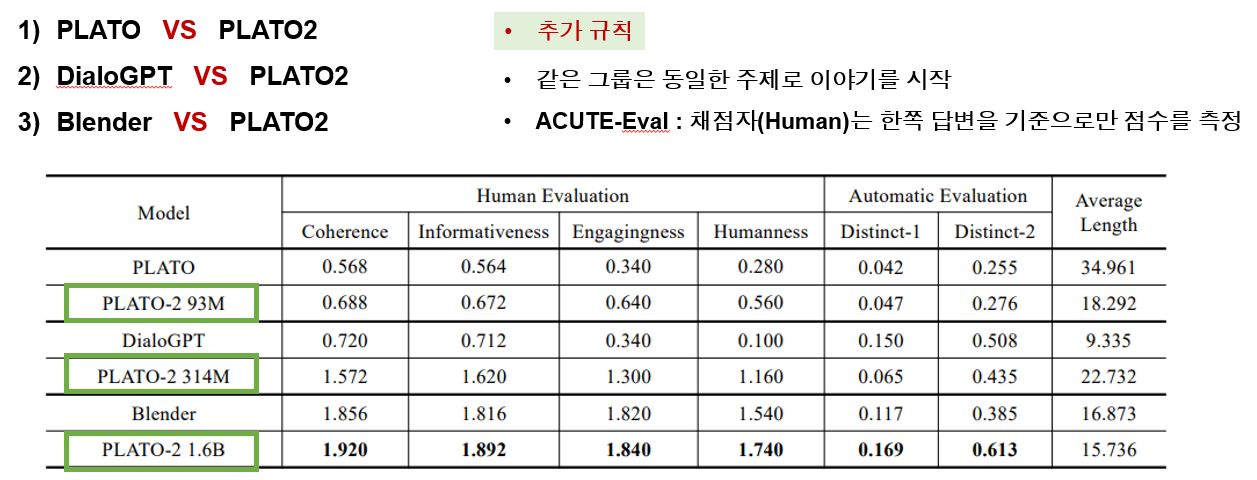
셀프 챗 평가에서는 3가지 그룹이 이 방식으로 평가가 진행되었습니다. 학습한 데이터, 모델 사이즈를 동일하게 맞춘 plato2 모델이 플라토1과 dialogpt, blender와 함께 비교가 되었습니다. human 평가에서 추가적인 규칙은 같은 그룹의 모델들은 동일한 주제로 이야기를 시작했고, ACUTE 평가 방식이 적용되어 채점자는 한쪽 답변을 기준으로만 점수를 측정하도록 적용되었습니다. 예시는 다음과 같은 데요 생성된 대화 자체에 대한 비교는 이후에 살펴보고 평가 방식만 살펴보면 동일 그룹이 "술 먹냐?" 라는 주제로 대화를 시작하게 됩니다. 그리고 어자피 P2 P1 모두 같은 모델이 생성한 대화이기 때문에 P1에 해당하는 발화를 기준으로 평가가 진행되었다라고 생각하시면 됩니다.

다시 결과를 살펴보면 첫번째 그룹에서는 동일한 사이즈의 플라토1과 플라토2의 대결이였습니다. 당연히 2가 성능이 훨씬 좋았고, 동일사이즈임에도 불구하고 이는 안정적인 Curriculum 러닝의 효과라고 볼 수 있습니다. 두번째 그룹은 dialoGPT와의 비교인데 이 모델은 Backward scoring방식을 통해 응답을 selection하기 때문에 거의 repetitive 형식의 대화를 생성하기에 interection evaluation에 좋지 않은 성능을 보였다고 합니다. 마지막으로 blende와의 비교 입니다. plato2가 어휘의 다양성 부분에서 훨씬 좋은 성능을 보였고 다른 그룹들과 다르게 확장된 모델 사이즈와 human 어노테이션 데이터가 성능향상에 많은 기여를 했다는 것을 알 수 있었다고 합니다.

다음은 두번째 평가 방식인 human-bot 방식입니다. 마이크로소프트에서 개발한 XiaoIce는 공개적 api를 제공하고 있지 않기 때문에 본 모델이 탑재된 weibo 플랫폼에서 사람과 모델(챗봇)이 대화한 내용을 collect 했다고 합니다. 결과를 살펴봤을때 retrieval 방식을 쓰는 XiaoIce 모델은 어휘 다양성 부분에서는 좋았지만 내용의 자연스러움과 관련된 human 평가에서는 모든 부분 PLATO2 보다 저조 했습니다.
-Static Evaluation

다음은 멀티턴 CONTEX가 주어졋을 때 적절한 답변을 생성하는지 알아보기 위해 Static 평가도 함께 진행되었는데, 플라토2와 meena,blender,DialoGPT가 함께 비교되었고 Meena, daily dialog sample, reddit에서 각 60개 샘플이 주어졌습니다. 이 결과로 플라토2는 다양한 시나리오에 높은 점수를 받았고, fleiss’s kappa average가 0.466으로 평가자들 대부분이 보통정도의 답변은 한다라고 이야기 했습니다.
💛Discussions
이제 몇가지 흥미로운 사실에 대해 이야기 해보겠습니다.
-Case Analysis
첫째로 blender와의 비교에서 똑같은 주제를 이야기 하더라도 대화의 방향이나 스타일이 많이 다르다는 것입니다. 블랜더의 대화를 보면 짧은 turn안에 빠르게 topic이 전환되었습니다. 예는 다음과 같은데 그 이유는 human annotation 데이터인 BST 때문이라고 이야기 하고 있습니다. 이 데이터는 두명의 사람이 파트너를 이루어 진짜 사람처럼 친해지기 위해 혹은 알아가기 위해 빠르게 personal한 정보를 주고 받는데 이는 어노테이션 환경 자체가 부자연스럽기 때문일 수도 있다 라고 이야기 하고 있습니다. 하지만 유용하지 못한 toxic을 없애고 사람 스타일을 닮기 위해 정말 좋은 데이터다라고 이야기 하고 있습니다

이에 반해 플라토2는 대화를 시작하고 topic이 일정하게 유지되며 대화가 깊게 진행됩니다. 본 모델은 다양성 및 정보성을 포함하는 one-to-many방식을 통해 생성되고 두번째 단계에서 evaluation 모델이 context와의 연관성을 추정하기 때문에 현재 topic을 고수하게 되는 경향이 있다고 이야기 합니다. 다음은 한주제로 얼마나 오래 이야기 했는지에 대해 비교를 해봤을 떄 플라토가 거의 3배 입니다.
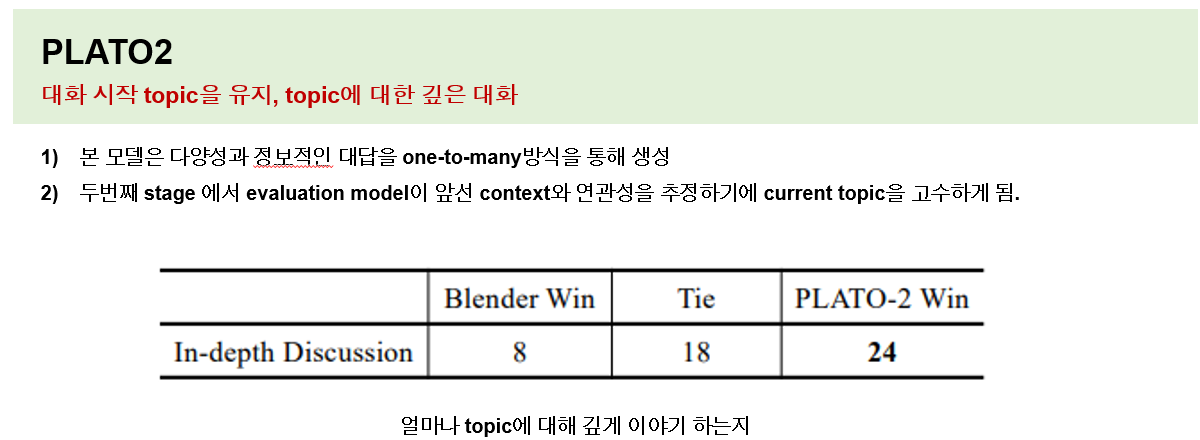
실제 생성된 대화로 진짜 그런지 살펴보겠습니다. 논문에서 나온 예시를 번역해보았습니다.

블랜더를 보면 실제로 toxic이나 bias를 없애려는 부분이 대화에서도 보이며, 플라토2는 정말 매니아가 아니면 모를 정도로 깊은 대화가 이어집니다.
-PLATO2 왜 좋을까?
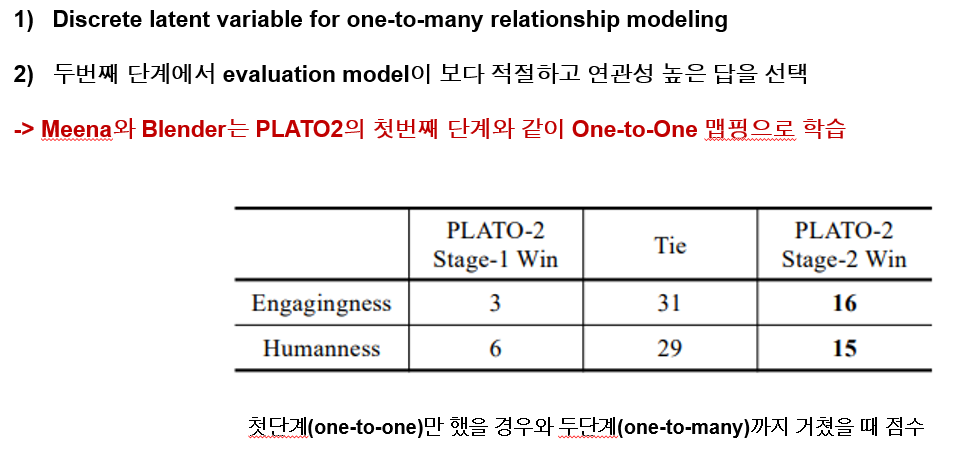
다음은 플라토가 왜 좋을까에 대한 분석인데요 이건 앞서도 이야기 했듯 전통적 방식과 다르게 일대다 형식으로 학습을 했다는 것 그리고 evaluation 모델을 통해 관련도 높은 정답을 택했다는 것입니다. 첫번째 이유를 증명하기 위해 단순 일대일 맵핑을 하는 일단계와 2단계까지 거친 모델을 비교했을 떄 월등히 2단계 까지의 모델이 점수가 높습니다.
-Further Exploration of PLATO-2

추가적으로 Knowledge grounded dialogue, task oriented 에서도 좋은 성능을 냈다는 것 입니다. 첫째로 일대다 방식의 맵핑이 knowledge grounded dialogue 에서도 적용이 가능했는데 대화 context와 이와 연결되는 knowledge snippet이 함께 주어지고 다른 점은 아까도 말했듯 input에 knowledge 정보가 함께 인코딩된다는 것입니다.
하지만 특정한 goal을 이뤄야하는 것이 task oriented의 목적이기 때문에 flow의 다양성을 줄이고 task를 완수하는데 초점을 맞출 필요가 있습니다. 이러한 부분은 첫번째 단계의 일대일 맵핑방식이 적용될 수 있습니다.
이를 통해 dstc9에서 3가지 track에 참가해 모두 일등을 했고 이번 dstc10 track2에서 세부트랙 두개 모두 우승을 했습니다.
'AI Researcher가 될끄야! > 대화 시스템' 카테고리의 다른 글
| [논문 리뷰] TOD-DA: Towards Boosting the Robustness of Task-oriented Dialogue Modeling on Spoken Conversations (0) | 2022.02.24 |
|---|---|
| [논문 리뷰]심층 신경망 기반 대화 처리 기술 동향 (0) | 2022.02.16 |
| [논문 리뷰] Learning knowledge bases with parameters for task-oriented dialogue system (0) | 2022.02.11 |
| Convlab2 - 대화 시스템 오픈 프레임워크를 소개합니다! (0) | 2022.02.11 |




댓글