안녕하세요😚
오늘의 논문리뷰는 AAAI 2022에 공개된 "Unifying Model Explainability and Robustness forJoint Text Classification and Rationale Extraction" 논문입니다.
💌 논문 링크 : https://arxiv.org/abs/2112.10424
💚Overview
간단하게 정리하자면 해결해야 하는 문제는 모델의 설명성을 위해 어떻게 적절한 판단근거를 추출할지, 다양한 adversarial attack에 모델은 정확한 예측을 할것인지 입니다. 여기서의 adversarial의 예는 이후에 보여드리도록하겠습니다. 그래서 본 논문에서는 바운더리 매칭 조건을 만들어 보다 정확한 판단근거를 인풋으로 부터 추출하고 두가지 방식이 합쳐진 Adversarial Training을 기반으로 하는 AT-BMC 모델을 제안합니다.
결과적으로 분류 TASK 자체와 근거 추출 TASK 모두에서 성능향상을 보이고 Attack success rate를 69퍼센트까지 줄였다고 합니다.
그럼 근거와 예측값은 어떠한 관계가 있을 까요?💁♂️
논문에서는 근거라는 것은 input의 부분집합중 하나로써 이 문장 하나만 있더라도 적절한 예측이 가능해야된다. 또 이것을 다른 말로 하면 모델이 예측하는데 있어 충분한 supporting하는 문장이여야 하고 예측 값과 긴밀하게 관계있는 근거를 추출하는 것이 모델 성능과 설명성 둘다에 많은 영향을 미친 다고 이야기 하고 있습니다.
기존 방식들은 파이프라인 형태로 이 문제를 많이 해결하고 있다고 이야기합니다. 파이프라인이라는 것은 예측의 단계와 설명의 단계를 따로 두는 것으로 이때 task label에 대한 의존성이 크고 하이퍼파라미터 변경에 민감하다는 문제를 가진다고 합니다. 이러한 특징은 adversarial attack에 취약하고 근거 추출시 경계정보가 무시된다는 단점이 있습니다.
기존 방식의 문제 😢

첫번째 문제를 예를 통해 살펴보겠습니다. 오리지널 텍스트에서 일부 단어들 정말 예측에 도움 안될 것 같은 고유명사 같은 애들을 바꾸었음에도 예측라벨이 긍정에서 부정으로 바뀌었습니다. 글의 의미는 거의 변하지 않았고, 사람이 근거로 뽑은 문장도 변하지 않았습니다. 즉 모델의 예측에 영향을 준 문장은 변하지 않았다는 것 입니다. 이랬을 경우 라벨과 설명이 맞지 않으며 더 이상 신뢰할 수 없다는 문제가 생깁니다. 이러한 경우를 adversarial attack이라고 하며 이러한 공격에도 견고한 모델이 되어야 합니다. 본 논문에서는 텍스트 수준의 perturbation과 임베딩 스페이스에서의 adversarial training을 믹스 하여 이러한 문제를 해결합니다.

두번째 문제는 경계정보가 무시된다는 것입니다. 어떠한 텍스트의 예측의 근거가 되는 문장 “this film is interesting and inspiring.”에서 interesting과 inspiring은 값은 에측 근거의 바운더리라고 할 수 있고 이모션 word에서 is와 마침표는 general한 토큰입니다. boundary position 모델링을 통해 매칭 제약 조건을 고려함으로써 글로벌한 시퀀스 라벨링 정보와 로컬 정보가 융합될 수 있도록 하는 방식을 통해 본 문제를 해결합니다.
💜Method
그럼 그 방식에 대해 자세하게 살펴 보겠습니다.

본 모델의 목적은 정확한 예측을 하면서 동시에 적절한 근거를 추출하는 것입니다. 타이타닉 영화에 대한 리뷰가 들어갔을 때 긍정인지 부정인지를 판단하고 이러한 판단을 이끌어낸 적절한 근거를 input에서 추출하는 것입니다.
input은 워드의 시퀀스로 L의 단어로 이루어진 인풋 X가 들어가게 되고 예측 라벨 ^Y과 단어 각각이 근거에 포함되는지 안되는지 0, 1로 예측되게 됩니다. 따라서 1로 예측되면 근거에 포함되는 단어라는 것입니다. 근거는 인풋 안에서 오버랩핑 되지 않는 여러 구일 수 있습니다.
이제 프레임워크를 따라가 보겠습니다. 전체 데이터셋이 인풋 X와 라벨 Y로 구성된 n개의 포인트로 구성되어 있다고 할 때 멀티 테스크 러닝 방식으로 prediction network f와 근거 추출 network g로 구성된 인코더 로 들어가게 됩니다. 하지만 이 네트워크들은 다른 디코더를 사용합니다.

그래서 output label에 대한 conditional likelihood은 수식 1과 같습니다. 이는 수식 2번과 같이 분해 될 수 있는데 이는 n개의 데이터들 모두 classification objective 함수에는 최적화 되지만 extraction objective 는 m개의 데이터 들에만 적용된다. 이는 사람이 어노테이션 한 것이 적더라도 학습이 가능할 수 있게 하기 때문입니다.
결과적으로 예측된 라벨이 text 시퀀스와 함께 근거추출 네트워크에 ^e를 예측하는데 사용됩니다.
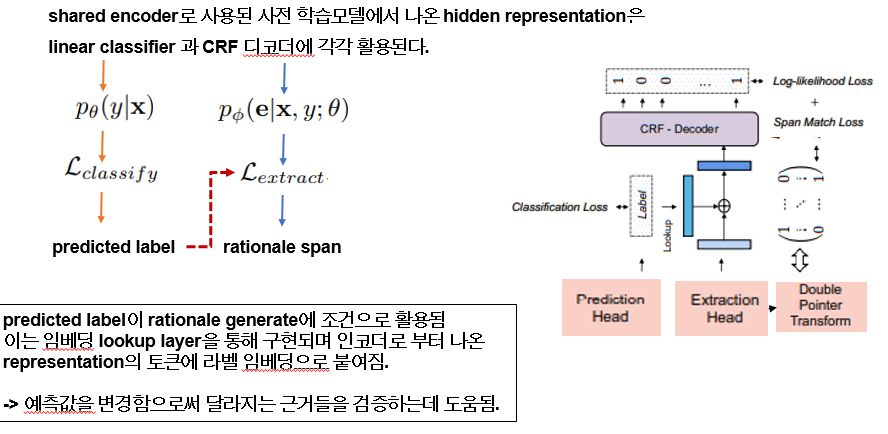
따라서 인코더에서 나온 hidden representation은 linear classifier에써의 크로스 엔트로피 로스와 네네가티브 로그 라이클리후드로 CRF 디코더에 각각 활용됩니다. 이 과정에서 예측 라벨이 임베딩 룩업 레이어를 거쳐 Representation 의 각 토큰에 붙여지면서 ^y이 변할 때마다 달라지는 근거의 변화를 볼 수 있도록 합니다.
그럼 여기서 이야기하는 핵심알고리즘 두개를 살펴보겠습니다.
💛Mixed Adversarial Training
mixed adversarial training은 텍스트 스페이스에 perturbation한 것과 임베딩 space에서 adversarial training 하는 방식이 합쳐지게 되는데 텍스트 스페이스에는 워드레벨에서 적용되고 발리데이션 데이터 에서는 하나의 edit만 적용되고 라벨은 보존된 상태에서 perturbation은 근거 외 문장에서만 진행됩니다.

이 perturbation 방식은 체크리스트 behavioral test 논문에서 나온 text attack 방식을 따르는데 이는 모델의 견고성을 attack 방식을 다양하게 하여 검증하는 방식입니다.
네가지 방식을 활용하는데 Name replacement, position replacement, number change, and contraction/expansion of named entities 방식을 활용합니다. 바뀐 단어들은 오리지널 과 pos 태그가 동일한 단어로 대체 됩니다. 한 데이터당 바뀐 퍼센트는 0.2 정도라고 합니다.

두번째는 임베딩 스페이스에서의 adversarial training입니다. 직접 인풋 텍스트에 perturbation하는 것이 아니라 임베딩 스페이스에서 효과적으로 regularization함으로써 인코더를 generalization하고 robust error를 줄일 수 있도록 합니다. 이는 3번 수식과 같이 목적함수를 정의 할 수 있는데 오리지널 데이터에서의 예측에 대한 크로스 엔트로피로스와 adversarial training에서의 로스를 최소화 합니다.
adversarial 트레이닝 로스는 4번과 같이 나뉘어 집니다. perturbation based adversarial training loss와 smoothing adversarial regularization term으로 나뉘게 됩니다. 여기서 각각 알파 베타는 파라미터입니다.
먼저 perturbation based adversarial training loss는 adversarial embedding에서의 cross-entropy loss 이고, 𝛿은 perturbation으로 나타낼 수 있습니다. 정리하자면 outer minimization은 SGD로 ! (3) inner maximization은 PGD로! (6)로 표현할 수 있겠습니다.
마지막으로 Standard objective와 adversarial objective 간의 교류와 label smoothness를 위해 7번 수식이 필요한데 이는 쿨백-라이블러(Kullback-Leibler) 발산 을 의미 하는데 전체 합은 1로 두개의 확률분포간의 차이를 계산하는 것이라고 보시면 됩니다. 즉 두개의 확률분포가 같아질 수 있도록 하는데 목적을 둡니다.
💙Boundary Match Constraint

두번째 핵심 방식으로 제안된 바운더리 매칭조건은 제가 보기에 더 정확하게 포지셔닝하기 위해 도입된 방식인 것 같습니다. crf는 관찰된 시퀀스특징이 주어졌을 때 라벨 시퀀스의 조건부 확률을 학습하게 됩니다. 이를 통해 start index와 end index를 정확하게 매칭하는 것을 목적으로 합니다.
가장 먼저 hidden representaion token들이 start가 될 확률을 예측하고 end 역시도 예측합니다.W는 학습된 weights이고 d는 히든 사이즈임. 각각의 로우는 포지션이될 확률 분포를 나타냅니다
그 후 각 ROW에 ARGMAX를 통해 정확한 스타트 앤딩 포지션을 추출합니다.

i와 j는 각각 L까지 있다고 했을 때 그다음 이진 분류 모델은 일치해야 할 확률을 예측하도록 훈련된다. 그래서 최종적으로 매치 로스는 골든 라벨 실제의 포지션 값들과 함께 계산이 됩니다. 정리하자면 모든 골든 라벨은 근거추출 네트워크와 예측 네트워크에 동일하게 주어지고 사람에 의해 표시된 근거 라벨도 따로 주어집니다. 이때 동일한 사전 학습 인코더를 사용해 파라미터값을 쉐어링 하며 추론 하는 동안 이 근거 라벨을 활용하여 예측한 근거 span과의 평가에 사용합니다.
🤎Dataset
사용한 데이터 셋은 “ Movie Reviews”데이터셋과 “MultiRC” 데이터셋 입니다. 이는 설명가능성에 대한 측정을 위해 TASK에 따른 예측라벨과 거기에 따른 근거가 함께 어노테이션 되어 있습니다.
데이터셋에 대한 더욱 자세한 내용은 다음 사이트 주소를 참조해 주세요! https://github.com/crazyofapple/AT-BMC/tree/main/datasets
GitHub - crazyofapple/AT-BMC: AAAI 2022 paper - Unifying Model Explainability and Robustness for Joint Text Classification and R
AAAI 2022 paper - Unifying Model Explainability and Robustness for Joint Text Classification and Rationale Extraction - GitHub - crazyofapple/AT-BMC: AAAI 2022 paper - Unifying Model Explainability...
github.com
🤎Experiments
성능을 평가하기 위해서 분류 TASK에서는 accuracy 와 근거를 추출하는 Task에서는 token F1을 통해 골든 라벨의 토큰과 실제 예측된 토큰의 차이를 비교합니다. 본 방법론은 BERT와 RoBERTa에 적용되었습니다. 이 방법론과 비교된 방식은 파이프라인 방식, information bottleneck 방식, FRESH 방식 , 약지도 학습 방식과 비교되었습니다.

두가지 데이터셋에 대하여 두가지 모델 모두 성능향상을 기록하였다는 것을 보입니다.


마지막으로 다양한 타입의 adversarial attack에서 모델의 견고성을 보이기 위해 실험을 진행 했는데 베이스라인은 imdb 데이터셋에 파인튜닝된 bert로 평가지표는 정확도, 공격에 대한 success rate 등이 있습니다.
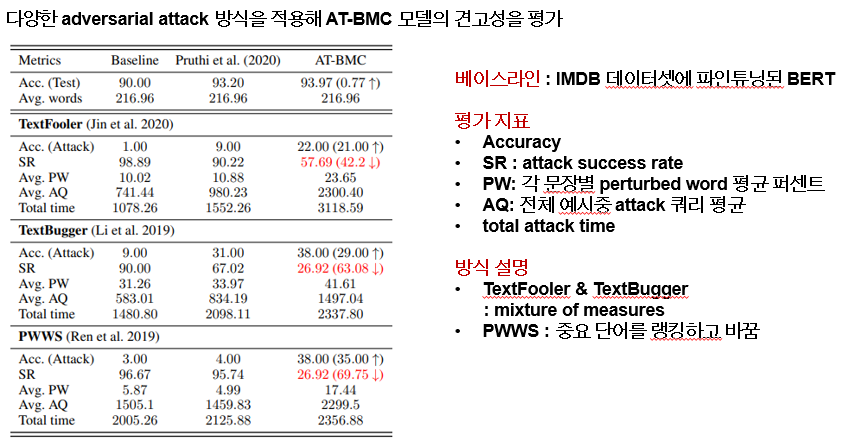
attack의 방식은 3가지 인데 텍스트풀러와 텍스트 버그는 measure들을 혼합하는 방식으로 워드 임베딩 거리와 pos 태그 매칭을 통해 대체 하는 방식입니다. pwws는 중요 단어를 랭킹하여 부분을 바꾸고 word saliency 와 synonym swap score로 단어의 중요도를 계산합니다. 본 실험은 movie review 데이터를 대상으로 평가가 진행되었습니다. 특히 pwws방식에서 SR 을 69퍼센트나 줄였다고 합니다. 이외에도 논문에서 적은 양의 근거 추출에도 불구하고 뛰어난 성능을 보였다고 추가 연구를 진행하였으며, 결과적으로 멀티 테스크러닝과 ADVERSARIAL Training이 성능향상에 가장 크게 기여했다고 합니다.



댓글