안녕하세요😚
오늘의 논문리뷰는 ACL 2020에 공개된 "ProtGNN: Towards Self-Explaining Graph Neural Networks" 논문입니다.
💌 논문 링크 : https://arxiv.org/abs/2112.00911
💚Overview
기존의 존재하는 많은 explanation method는 post-hoc 방식에 치우쳐 있습니다. 따라서 다른 모델이 설명을 제공하기 위해 별도로 GNN을 학습해야 합니다. 하지만 이러한 방식들은 오리지널 모델의 Reasoning process를 보이는데 실패하는 경우가 많습니다.

따라서 본 논문에서는 프로토타입 러닝 방식을 적용한 Prototype Graph Neural Network를 공개했습니다. 해석 가능성을 오리지널 모델에 Built in 방식으로 보였습니다. 또한 설명가능한 모델 중 case-based 방식으로써 분류 task를 진행되며 함께 설명가능성을 제공합니다.
그 방식을 간단하게 설명 드리면 ProtGNN의 prediction은 학습된 프로토타입과 latent space에서 지교를 통해 얻어지게 됩니다. 또한 추가적으로 설명력을 높이기 위해 conditional subgraph sampling module이 추가된 protgnn+도 공개하였습니다. 이는 프로토타입과 어떤 부분이 가장 비슷한지를 알려줍니다. 차이를 다시 설명하자면 ProtGNN은 각 클래스별로 K의 프로토 타입을 만들어서 이 프로토타입과 인풋 그래프를 비교하여 분류와 설명을 제공하지만 이러한 부족한 설명을 Prot GNN+에서는 서브 샘플링 모듈을 활용하여 어떠한 부분이 가장 비슷했는지를 측정함을 통해 설명성을 제공합니다.
결과적으로 이 다양한 벤치마크 데이터셋에서 정확도와 설명력을 향상 시켰으며, 정말 사람이 판단을 내리는 결과와 비슷하게 판단할 수 있도록 했습니다.
💛과거의 방식
과거 gnn을 활용하여 설명성을 제공하는 방식들은 크게 3가지 방식이 있습니다. 가장 먼저 gradients/features-based method는 그래디언트나 특징값을 활용해 각기 다른 input에서 그 중요성을 보여주는 방식입니다. 오른쪽 그림에서 강아지에 해당하는 특징 값이라고 할 수 있습니다. 다음은 perturbation 방식입니다. 판별 값은 유지한 상태에서 인풋요소들의 중요도를 측정하는 방식입니다.

다음은 decomposition 방식입니다. 오리지널 모델의 예측값을 특정 구간으로 decompose하고 이러한 구간을 그래프노드와 엣지로 연결하면서 설명을 제공합니다.
하지만 이러한 방식은 post-hoc방식으로 판별 값이 오리지널 모델에서 나온 이후 설명성을 제공하는 모델이 별도로 설명할 수 있도록 주어집니다. 따라서 정확하게 오리지널 모델에 맞지 않을 수도 있습니다. ProtGNN은 학습시킨 데이터를 케이스화 하고 이것을 Input과 비교하여 예측결과도 내고 설명을 제공하는 built in 방식입니다.
💜Method
이제 protGNN의 작동방식을 설명해드리도록 하겠습니다. 가장 먼저 전반적인 ProtGNN의 구조를 설명 드리겠습니다.
라벨링된 트레이닝 데이터셋이 X, Y 페어로 있다 했을 때 X는 Input graph가 되고 y는 1 부터 C 중 하나의 라벨이라고 생각하시면됩니다. 이는 분류와 설명을 위해 사용됩니다. Input 그래프가 들어왔을 때 각 프로토타입과의 유사성이 latent space 위에서 측정됩니다. 그 이후 새로운 instance에 대한 예측과 설명성이 비슷한 프로토타입 그래프 패턴을 통해 얻어집니다.

이 구조도가 ProtGNN의 전반적 구조도 인데요 가장 크게 세 부분으로 나눌 수 있습니다.그래프 인코더 F, 프로토타입 레이어 G 그리고 Fully connected layer c로 구성됩니다. 최종적으로 소프트 맥스가 더해져 각 아웃풋의 확률이 구해지고 최종적으로 분류가 되게 됩니다. 인풋 그래프 x가 주어지면 그래프 인코더 f는 그래프 임베딩 h로 맵핑 시킵니다. 앤코더 모델은 gnn 어떤 모델도 가능합니다 예를 들어 GCN, GAT, GIN등이 가능합니다. 최종적으로 그래프 임베딩 j는 sum이나 max pooling 과정을 통한 last GNN layer에서 구해집니다.
프로토 타입 레이어에서는 각 클래스마다 정해진 갯수의 프로토 타입을 할당합니다. 최종적으로 학습된 ProtGNN은 각 클래스들은 학습된 프로토타입들의 집합으로 표현될 수 있습니다. 프로토 타입은 가장 관련있는 그래프 패턴 특징을 담게 됩니다. 각 입력에 대한 임베딩 h를 프로토 타입 레이어는 프로토 타입들과의 유사성 점수를 계산합니다. 수식은 다음과 같습니다. 여기서 pk는 k번째 프로토타입으로 그래프 임베딩 h와 동일한 차원을 가집니다. 유사성 함수는 pk-h 거리를 감소할 수 있도록 설계되었지만 0보다는 항상 큽니다. e는 가장 작은 값으로 설정되었습니다. 최종적으로 유사성 점수와 함께 fully connected layer는 softmax를 계산하여 각 아웃풋에 대한 확률을 내놓습니다.

다음은 목적 함수에 대해 알아보겠습니다. 목적은 최종적으로 ProtGNN이 정확도와 설명성 모두를 향상시키는 것입니다. 먼저 정확도 부분에서는 Cross entropy loss를 트레이닝 셋에서 최소화 시키는 것입니다. 설명성을 위해 프로토타입을 만드는 부분에 있어서는 3가지 로스가 적용되는데 가장 먼저 cluster cost 입니다. 이는 각 그래프 임베딩이 해당 되는 클래스 안에서의 적어도 하나의 프로토타입과 가까워 질 수 있도록 합니다. 두번째 separation cost는 그래프 임베딩이 해당되는 클래스 프로토타입과 멀어지게 하는 것입니다. 마지막으로 학습된 프로토타입들은 서로 매우 가까이 위치할 수 있기 때문에 다양성을위해 diversity loss를 추가하여 너무 가까워 지는 것을 방지합니다.
최종적으로 목적함수는 다음과 같이 정의 됩니다. 여기서의 람다 값들은 하이퍼 파라미터입니다. Py는 각 클래스별 프로토타입 집합이고, smax는 코사인 유사도의 threshold입니다
✅ Prototype Projection
다음은 프로토 타입 프로젝션입니다.
학습된 프로토타입 그 자체는 바로 설명 가능하지 않습니다. 따라서 프로젝션 과정을 학습과정에 디자인 하였습니다.
구체적으로, 우리는 각 프로토타입 pj(pj → Pk)를 pj와 동일한 클래스의 가장 가까운 latent training subgraph에 투영합니다(Eq. (7 참조). 이러한 방식으로, 우리는 개념적으로 각 프로토타입을 하위 그래프와 동일시할 수 있으며, 이는 더 직관적이고 인간이 이해하는 방식입니다. 계산 비용을 줄이기 위해, 투영 단계는 몇 번의 훈련 기간마다 수행됩니다.

이미지와 같이 그리드 기반 데이터가 아니기 때문에 본 논문에서는 “Monte Carlo tree search” 알고리즘을 적용했습니다. 이를 통해 subgraph를 exploration할 수 있도록합니다. 가장 먼저 루트가 입력 그래프와 연결되고 다른 각 노드가 탐색된 하위 그래프에 해당하는 검색 트리를 구축한다.
search tree안에 있는 각 노드를 Ni라고 정의하며 N0은 루트노드를 의미합니다. 엣지들은 서치 트리 안에서 pruning action으로 정의됩니다. 검색 트리에서 자식 노드와 관련된 그래프는 부모 노드에 해당하는 그래프에서 노드 제거를 수행하여 얻을 수 있다. 검색 공간을 제한하기 위해 다음 두 가지 제약 조건을 추가했습니다. Ni는 연결된 서브그래프여야 하며 투영된 서브그래프의 크기는 작아야 한다는 것입니다
search process가 진행되면서 exploration과 검색 공간을 줄이기 위해 visting counts와 reward를 기록합니다. 세부적으로 노트와 프루밍 엑션 페어는 서브그래프 Nj에서 엑션 aj를 Ni로 부터 함을 통해 얻을 수 있습니다. 이때 각 페어에 대하여 4가지 값을 기록합니다.

MCTS 서치는 가장 가까운 subgraph를 찾기 위해 두 단계로 진행됩니다. forward pass에서는 루프 에서 leaf node Nl까지의 패스를 고릅니다. 결과적으로 Ni에 행해지는 action은 다음과 같이 골라집니다.여기서 u를 살펴보면 람다는 exploration and exploitation 사이를 조절합니다. 이 전략은 자식노드를 고를때 적게 방문한 횟수로 골라서 각기 다른 프루밍 엑션을 취하려는 반면에 높은 유사성을 가질 수 있도록 엑션이 선택됩니다.
backward pass에서는 선택된 모든 노드와 에션 페어가 패스에 따라 업데이트 됩니다.
마지막으로, 우리는 모든 확장된 노드에서 유사성 점수가 가장 높은 하위 그래프를 새로운 투영 프로토타입으로 선택합니다.
✅ Conditional Subgraph Sampling module
다음은 ProtGNN+에 적용된 방식으로 단순 프로토타입별 유사도 점수를 계산하는 것 뿐만아니라 Input 그래프에서 어떠한 부분이 각 프로토 타입과 유사했는지를 보여줍니다. 따라서 conditional Subgraph Sampling module의 아웃풋은 각 프로토타입에 맞는 각기 다른 subgraph 임베딩을 내놓습니다. MCTS는 계산시간이 오래 걸리기에 대신 parameterized한 방식을 활용하여 주어진 프로토타입에서 가장 비슷한 subgraph를 고를 수 있도록 합니다.
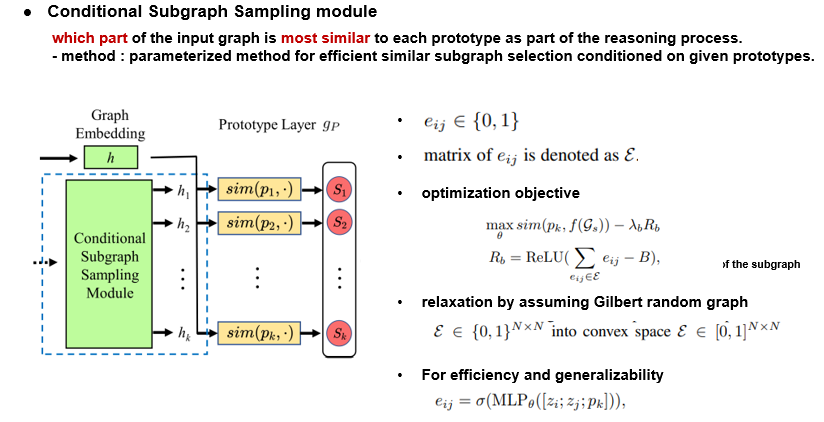
먼저 eij가 이진 변수이고 노드 I와 J에서 선택되었는지 아닌지의 여부를 나타내고 matrix eij는 결국 E를 나타냅니다. 목적함수는 다음과 같이 정의되는데 Gs는 adjacency matrix가 e인 선택된 subgraph입니다. b는 subgraph의 맥시멈 사이즈 입니다.
조합적이고 이산적인 그래프의 특징은 목적함수를 최적화 하기 힘들게 하기 때문에 gilbert random graph를 추정함을 통해 relaxation을 합니다. 이때 각 엣지들의 상태는 서로 독립적이여야 합니다. 또한 일반화를 통해 eij를 학습하기 위한 dnn을 적용합니다.
✅ Training Procedures

트레이닝 알고리즘을 요약해 보겠습니다. 가장 먼저 랜덤하게 모델 파라미터를 초기화 합니다. FC레이어의 Weight matrix가 wc라고 할 때 wc kj는 j번째 프로토타입과 클래스 k의 로짓 값입니다. 만약 j 번째 프로토타입이 해당 k 의 프로토타입 그룹에 있을 경우는 1로 초기화 하고 아니라면 0으로 셋팅합니다. 이러한 wh의 초기화는 클래스 k에 속하는 프로토타입이 클래스 k의 특징과 의미론적 구성을 학습할 수 있도록 장려합니다. 학습이 시작되면 그래디언트 티샌트를 아까 보셨던 목적함수를 최적화 하기위해 시행됩니다.
그 후 프로젝션 에포크 Tp보다 커지면 프로토 타입 프로젝션 스텝을 트레이닝 과정에서 few epoch에 수행합니다. 더욱 나아가 protGNN+를 위한 서브 그래프 샘플링 모듈이 웜업 에포크 보다 커지면 시행됩니다.
💜DATA & Experiments

3가지 데이터셋(분자구조-독성예측, 텍스트-긍,부정예측,이상한 노드 분류)과 3가지 방식을 Backbone으로 했을 때를 비교 했습니다.
오리지널 보다는 대부분 ProtGNN과 ProtGNN+가 좋은 성능을 보였습니다. 실제 예시를 살펴 보면 다음과 같습니다.
1) 분자구조에서 독성을 예측하는 부분

실제 no2와 carbone ring이 만나면 돌연변이가 생긴다는 결과가 있는데 실제로 돌연변이 프로타입에서 이러한 특징을 잘 담아냄을 볼 수 있습니다. 그리고 인풋과도 그러한 부분을 중심으로 판단을 내린다는 것을 알 수 있습니다.
2) 텍스트의 긍정, 부정 분류

실제 input 그래프의 내용을 보면 손자들이나 조부모들은 지루할까 걱정할 필요가 없다. 라는 말이고, 긍정적인 프로토타입과 비슷한 부분을 보면 "never worry about bored" 부분이라는 것을 정확하게 짚어 냅니다.
3) 프로토 타입을 얼마나 잘 추출하는가

실제로 t-SNE를 활용하여 시각화 했을 때 긍정, 부정의 클래스 별로 적절하게 프로토타입을 잘 주출하고 있음을 볼 수 있습니다.
🧡Conclusion

따라서 정리하자면 본 논문은 그래프 방식을 활용하여 설명성을 제공할 수 있는 논문 입니다. 각 클래스별로 K개의 프로토타입을 만들고, 인풋을 K개의 프로토 타입과 비교하여 유사성을 계산하여 판단을 합니다. 또한 각 프로토타입과 어떠한 부분이 가장 유사했는지를 알려주는 ProtGNN+까지 발전 시킨 논문입니다!



댓글