안녕하세요😚
오늘의 논문리뷰는 ACL 2020에 공개된 "Dialog Inpainting: Turning Documents into Dialogs" 논문입니다.
💌 논문 링크 : https://arxiv.org/abs/2205.09073
💚Overview
본 논문에서 가장 크게 지적하는 것은 대화형 QA TASK를 구축하기는 매우 힘들다는 점입니다. 이러한 데이터를 구축하기 위해서는 전문 온라인 포럼에서 데이터를 긁어 올 수 있는데 이는 개인적인 의견이나 주관적인 의견이 많고, 전문가가 제작할 경우 질은 높지만 굉장히 노력과 비용이 많이 들어간다는 문제점이 있습니다.

하지만 전문가들이 작성한 높은 퀄의 문서들은 위키피디아 같은 곳에 있고 독자가 궁금해 하는 사항을 기반으로 내용을 잘 작성해 놨습니다. 따라서 이러한 Document를 활용하여 document를 작성한 writer와 상상속의 독자가 나누는 두가지의 ConvQA data set을 생성하는 것이 목적입니다. 즉 ConvQA 입장에서보면 상상의 독자가 질문을 던지는 사람이고 Writer가 주어진 document에서 적절한 답변을 제공하는 역할이라고 할 수 있습니다.
따라서 document에서 이러한 방식으로 대화셋을 생성함을통해 위키 다이어로그, 왭 다이어로그를 만들어 총 19 밀리언 information seeking dialog를 구축하였습니다. 구축된 데이터로 ConvQA RETRIEVAL System 사전학습 및 파인튜닝하여 벤치마크에서 sota를 찍었다는 것을 보입니다.
핵심적인 내용은 document를 활용해 ConvQA 대화를 만들기 위해 유저의 질문을 예측하고 Document를 활용해 정답을 채우는 “Dialog Inpainting”방식을 제안했다는 것 입니다.
💛Dialog inpainting
여기서 가장 핵심이 되는 “Dialog inpainting”이라는 개념 부터 알아보겠습니다.
하나의 document를 대화로 바꾸기 위해서 본 연구에서는 하나의 가정을 합니다. 대화는 문서의 작성자인 writer와 imagined reader 즉, 질문하는 사람의 대화로 구성됩니다.

document의 각 부분부분이 writer의 답변이 되고 imagined reader의 질문은 비어 있는 상태에서 이 질문을 예측하는 것이 inpainting의 목적입니다. 이는 전화를 엿듣는 상황과도 비슷한데 누군가가 옆에서 통화를 할때 옆에 있는 사람의 말은 들리지만 전화를 하는 상대의 말은 들리지 않습니다. 하지만 우리는 문맥과 옆 사람의 발화를 통해 전화 상대의 말도 예측해 볼 수 있습니다.
따라서 이러한 task를 inpainting 이라고 하며 이는 비전에서 사진 속 구멍 뚫린 부분을 채워 넣는 task로 부터 유래 되었다고 합니다. 즉 inpainting 모델을 학습시킨 다는 것은 대화에서 누락된 발화를 예측하는 방식으로 모델이 학습을 진행하고 추후 문서에서 비롯될 수 있는 질문을 예측하여 생성된 질문과 이에 맞는 문서 속 문장이 답변으로 생성되어 하나의 대화 셋이 완성되는 형태입니다.
이러한 결과로 Wikipedia and the web에서의 passages들을 이용해서 WikiDialog and WebDialog를 구축하였으며 two datasets totalling 19M+ dialogs — 1,000x 기존에 존재하는 ConvQA데이터셋 보다 1000배 크게 만들었습니다. 데이터셋은 대화적인지 정답이 적절한지의 기준으로 평가되어 크라우드 소싱된 데이터보다는 좋다라는 결과를 얻었습니다. 본 데이터로 ConvQA syste을 학습시켰을때 Conv retrieval benchmark에서 표준 평가 지표에서 최대 40%의 상대적 이점 제공할 수 있다는 것을 보였습니다. 또한 제로샷 트레이닝에도 좋은 결과를 보였는데 파인튜닝된 retriever들이 in domain ConvQA 데이터셋이 없더라도 95%정도의 성능을 보였다고 합니다
💜Method
그래서 이제 세부적으로 Dialof inpainting 방식을 살펴보도록 하겠습니다.
가장 큰 목적은 부분적인 대화를 complete한 대화로 완성 시키는 것입니다.
완성된 대화 d 가 있다고 할때 예를 들어 3번과 5번 발화가 masked 되면 dm(3,5)로 표현한다고 하고 이 3번과 5번 발화를 예측하는 것이 본 task의 목적입니다.

따라서 대화를 reconstruction하기 위해 학습이 진행됩니다. 가장 먼저 전체 대화에서 하나의 발화를 가리고 이 masked 된 발화를 예측할 수 있도록 학습되는데 이는 bert의 mlm 방식과 유사하나 문장을 가리고 생성한다는 점이 조금 다릅니다. 즉 t 시점의 발화를 마스크하고 다음과 같은 확률 분포를 따르는 생성 모델이라고 할 수 있습니다. 여기 하단의 big D는 완벽한 dialog set이고 ut는 d로 부터 랜덤으로 샘플링 된 발화입니다
모델은 t5를 통해 학습이 진행되었고, 스피커를 구분하기 위해 xy 페어로 나누어 speaker id를 붙여 input으로 학습이 되었습니다. 따라서 input은 다음과 같고 output은 masked된 발화 부분 입니다.


이제는 실제 학습된 inpainter을 통해 문서를 대화로 바꿀 방법에 대해 소개 합니다. 즉 모델의 추론과정이라고도 할 수 있겠습니다. 문서들의 각 문장들은 imagined reader의 질문에 대한 답변들 즉 writer의 발화 후보들입니다. 이러한 문장들이 답변으로 유발되기 위해 상상의 독자의 발화를 예측해야 하기에 다음과 같이 독자의 질문 부분을 마스크 형태로 넣어줍니다.

하지만 첫 발화가 상상의 독자일 경우 어떤 주제로 해야할지 모르기 때문에 가장 처음에는 프롬프트 식으로 넣어줍니다. 예를 들어 다음과 같습니다. 이 그림 예시는 프래시맨 15에 대해 이야기 하겠다고 합니다. 반드시 첫 발화는 writer의 프롬프트로 고정됩니다.
또한 모델은 한번에 한 발화만 예측할 수 있기에 autoregressively하게 예측이 진행됩니다. 처음에는 다음과 같이 들어 u1을 예측하고 두번째는 u1을 포함한 상태에서 u2를 예측하는 식입니다. 이렇게 해서 전체 대화 셋이 생성되는 방식입니다.
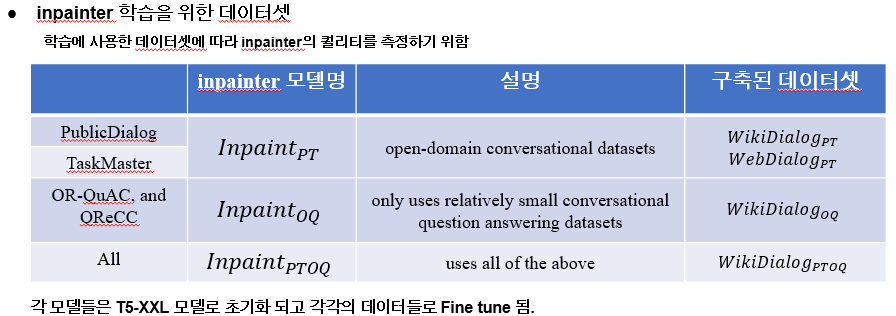
inpainter를 학습시키기 위해서 사용된 데이터는 3개입니다. 여러개의 데이터셋을 사용한 이유는 학습한 데이터에 따라 inpainter의 퀄리티를 확인 하기 위해서 입니다. 가장 먼저 PublicDialog와 TaskMaster는 오픈 도메인 대화 데이터셋입니다. 즉 qa 데이터를 포함하지 않습니다. 그리고 다음은 or-quac와 qrecc입니다. 이는 작은 양의 convQA 데이터셋입니다.
그리고 모든 데이터셋 통합입니다. 이 각각의 데이터로 훈련된 모델이 다음과 같고 이 모델의 추론을 통해 생성된 데이터 들이 다음과 같습니다.
각 inpainter 들은 T5-XXL 모델로 초기화 되고 파인튜닝되었습니다.

데이터셋 구축을 위해 사용된 DATA 셋들로는 다음과 같습니다. 즉 이 데이터가 Document에서 대화로 변하는데 사용된 데이터셋 입니다.
💜 Experiments
데이터셋 자체를 평가했을 때 각 inpainter에서 나온 데이터셋과 표준 convqa 데이터를 비교해봤습니다 각각 질문에 대한 항목별 퍼센트와 신뢰도를 표시하고 있습니다. 질문들은 4가지 정도였는데 질문들이 정보를 적절히 seeking하고 있는가, 질문이 대화와 관련있는가, 질문이 구체적인가, 질문에 대한 답이 제대로 되었는가로 평가를 진행했습니다.
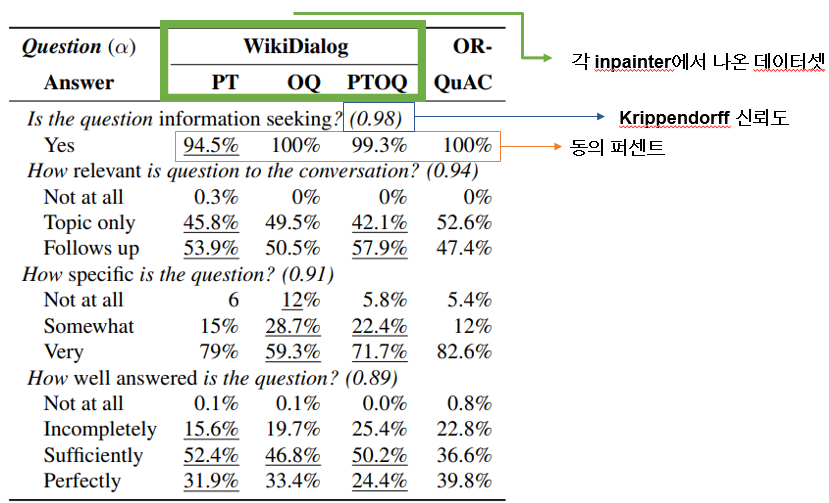
모든 항목이 표준 convqa보다 높지는 않지만 꽤 높은 평가를 받고 있습니다.
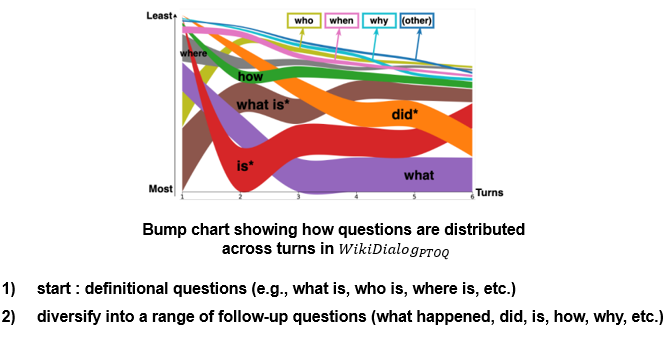
재미있는 분석점을 살펴보면 턴을 기준으로 시작 턴에서는 대부분 정의에 관련된 질문이 많고 뒤로 갈 수록 후속 질문이 많은 경향을 보였습니다. 생성된 것임에도 불구하고 정말 사람 대화와 비슷하죠?
🧡Application
본 데이터를 실제 ConvQA 시스템에 적용 시켰을 때를 알아보겠습니다.

그래서 convQA는 두가지 TASK로 구성되는데 적절한 지식을 retrieve하고 generation 하는 것인데 여기서는 retriever task에 초점을 맞춥니다. 따라서 모델은 input으로는 dialog history와 passge를 받고 outpu으로 socore 즉, passge와의 연관성 점수를 내뱉습니다. 가장 높은 점수의 passag가 select 됩니다. 여기서는 dialogue history가 하나의 쿼리 처럼 사용됩니다. 다른 연구들에서는 유저의 질문만 history로 사용하는 경우도 있는데 여기서는 system 발화도 포함합니다. 모델은 두가지로 구성되는데 가장 먼저 dual encode를 통해 초기 후보들을 고릅니다. 그 후에 cross-attention 방식 ranker를 통해 재점수를 냅니다. 모델을학습 시키기 위해 q,p 페어로 만들었는데 q는 dialog history, p*는 관련된 passage 입니다.

사전 학습과 파인 튜닝을 위해 기존의 데이터셋을 좀 정제 할 필요가 있었는데요 기존의 데이터셋이 프롬프트 발화를 시작으로 다음과 같이 구성이 되어있을때 u부분은 질문이고 s는 오리지널 본문에서 따온 구성요소로써 각 질문에서 p를 당연히 적절히 고를 수 있어야 한다. 따라서 대화 히스토리 q를 구성하는 작업에서 질문으로 끝날 수 있도록 구성 하고 이에 맞는 본문 p를 매칭하는데 오리지널 전체를 쓰지 않고 이전 발화 에서 정답이 되었던 p들은 제외하고 나머지 문장들을 이은 본문을 매칭한다. 따라서 이러한 방식으로 변형된 inpainted data를 사전학습하고 각 ConvQA DATASET에 파인튜닝 시켰다
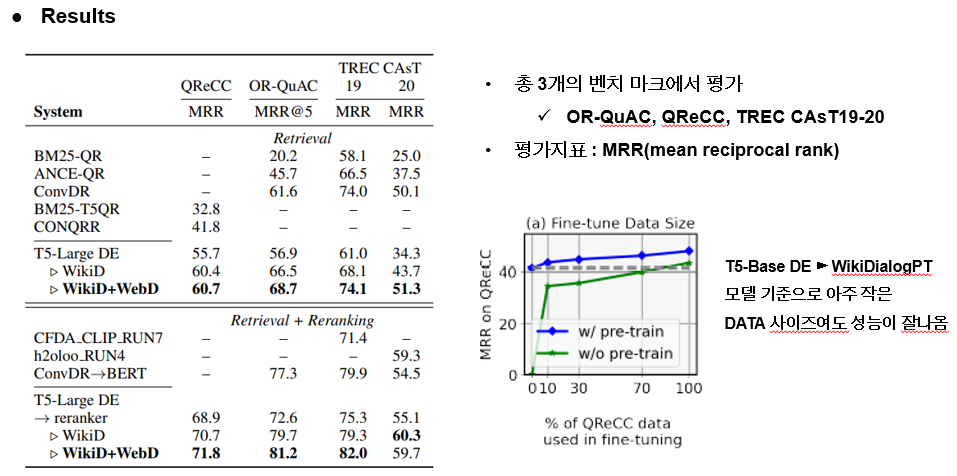
결과적으로 ConvQA 벤치 마크에서 각 Retrieval 모델들과 비교해 봤을 때 단순 리트라이벌만 하는 것과 리랭킹 과정이 한번 더 있는 모델들과 비교를 각각 진행했을 때 모든 부분에서 sota를 달성했다는 것을 보입니다. 이때의 평가지표는 MRR이 사용되었습니다.
추가적인 실험으로는 ConvQA 데이터를 학습하지 않은 Inpainter에서 나온 데이터셋을 학습한 모델도 전체 데이터에서 10퍼센트도 파인튜닝에 활용하지 않았음에도 높은 성능을 보임을 확인 할 수 있었다고 합니다.
🧡Conclusion
따라서 본 논문의 결론 및 기여점을 요약하자면 다음과 같습니다!
본 논문이 거의 ICML2022에서 BEST 페이퍼라고 뽑혔던데(교수님께 들음) 여러분들도 많은 도움 되시길 바래요!



댓글